RDS(MySQL) から BigQuery へ1日1回データを同期して、データ分析やレポート系の処理で利用することになりました。
構成
以下の構成でデータを同期することにしました。
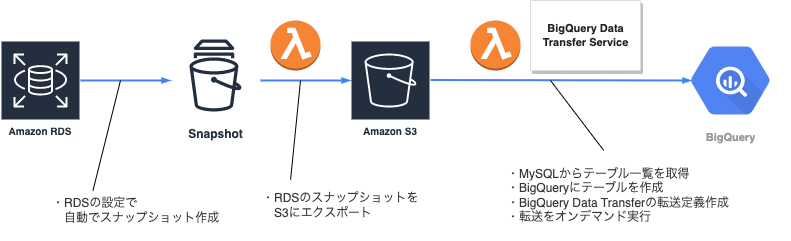
- 要件1: データの断面は合わせたい
- 元々はEmblukを使って直接同期しようと考えていたが、Embulkだとテーブル毎にデータを同期することになり、テーブルによってデータの断面が微妙にずれるため断念
- CSV 形式でダンプして、Embulk で同期することもできそうだが、元々自動でスナップショットが取られているのでそれを利用することにした
- => スナップショットを parquet 形式で S3 にエクスポートすれば、BigQuery Data Transfer Service を使って BigQuery に取り込むことができるので、採用
- 要件2: コストを抑えたい
- 定額利用料がかかるサービスは使うことはできない
- => ほぼ無料で使える Lambda を採用
- => データ転送料くらいしかコストのかからない BigQuery Data Transfer Service を採用
Amazon RDS => Snapshot
RDSのデータベースを作成する際に 自動バックアップを有効 にしておくと、1日1回自動で Snapshot を作成してくれるので、それをそのまま利用します。
Snapshot => S3
Lambda で aws-sdk を利用して、スナップショットを S3 にエクスポートします。
まず、Lambda の実行ロールに以下の Policy をアタッチする必要があります。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iam:PassRole",
"rds:DescribeDBSnapshots",
"rds:StartExportTask"
],
"Resource": "*"
}
]
}また、スナップショットを S3 にエクスポートする際に指定する以下の二つのリソースが必要です。
- IAM Role
- 以下の policy をアタッチ
{ "Statement": [ { "Action": [ "s3:PutObject*", "s3:ListBucket", "s3:GetObject*", "s3:GetBucketLocation", "s3:DeleteObject*" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::xxxx-bucket/*", "arn:aws:s3:::xxxx-bucket" ], "Sid": "" } ], "Version": "2012-10-17" } - 信頼関係に以下を指定
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "export.rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
- 以下の policy をアタッチ
- KMS の key
- 対称、暗号化&複合化の設定で作成
最後に、エクスポートを開始する Lambda を実装します。
コアな部分を抜き出して載せておきます。typescriptで実装してあります。
const rds = new AWS.RDS({ region: 'ap-northeast-1' });
const response = await rds.describeDBSnapshots({ DBInstanceIdentifier: 'xxxxxx' }).promise();
const snapshots = response['DBSnapshots'];
const latestSnapshot = snapshots?.sort((s1, s2) => (isBefore(s1.SnapshotCreateTime as Date, s2.SnapshotCreateTime as Date) ? -1 : 1))[0]; // isBefore は date-fns
const response = await rds
.startExportTask({
ExportTaskIdentifier: 'xxxxxx',
SourceArn: snapshot.DBSnapshotArn,
S3BucketName: 'xxxx-bucket',
IamRoleArn: 'xxxxxx',
KmsKeyId: 'xxxxxx',
S3Prefix: 'xxxxxx',
})
.promise();
console.log(`response: ${JSON.stringify(response)}`);こちらを実行すると、 S3 へのエクスポートが開始されます。
この Lambda の実行自体は数秒で終わりますが、エクスポートには20〜30分ぐらいかかるので注意が必要です。
S3 => BigQuery
次は、S3 にエクスポートしたスナップショットデータを BigQuery に同期するための Lambda を実装していきます。
BigQuery Data Transfer Service を使って同期するのですが、処理の流れは以下のようにしました。
- BigQuery にテーブルが存在していない場合作成する
- 既存の転送定義が存在する場合は、転送定義を削除する
- 転送定義を作成する
- 転送を開始する
転送定義を毎回削除=>作成しているのは、転送定義中のS3のスナップショットのパスが、毎日異なっており、そこを更新する必要があるためです。作成or更新を判断して利用するAPIを使い分けるのでもいいと思います。
事前準備
- GCP でサービスアカウントを作成する
- BigQuery にアクセスして、テーブルを作成したり、転送定義を作成/開始したり権限が必要です
- 必要なロールは以下の二つでした
- BigQuery 管理者
- BigQuery Data Transfer Service エージェント
- AWS で IAM User を作成する
- BigQuery Data Transfer が AWS S3 にアクセスしたり、暗号化されたファイルを複合するための権限が必要です
- 以下のようなポリシーを設定する必要があります
{ "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::xxxx-bucket/*", "arn:aws:s3:::xxxx-bucket" ], "Sid": "" }, { "Action": "kms:Decrypt", "Effect": "Allow", "Resource": "arn:aws:kms:xx-xxxxxxxxx-x:xxxxxxxxxx:key/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx", "Sid": "" } ], "Version": "2012-10-17" }
- GCP で Big Query と BigQuery Data Transfer Service の API を有効にする
- BigQuery で同期先のデータセットを作成する
ここまでで、事前準備は終わりです。次は Lambda を作成していきます。
BigQuery にテーブルが存在していない場合作成する
まずは、BigQuery にテーブルが存在しなかったら、作成する処理になります。
該当部分を抜粋すると以下のような感じになります。
// MySQLからテーブル名の一覧を取得
const [rows] = await con.execute('show tables from xxxxxx;'); // con は、MySQLのDBベースへのコネクションです。これを取得する部分は端折ってます
const tableNames = rows.map((row) => row['Tables_in_xxxxxx']);
// BigQueryのクライアントを初期化
const auth = googleAuth('bigqeury-projectname-xxx', 'service-account-email-xxx', 'service-account-private-key-xxxxxx', [
'https://www.googleapis.com/auth/bigquery',
'https://www.googleapis.com/auth/cloud-platform',
]);
const client = (await auth.getClient()) as JSONClient;
const bq = tnew BigQuery({ projectId: 'bigqeury-projectname-xxx', authClient: client });
// テーブルがなかったら作成
const dataset = bq.dataset('dataset-xxxx');
for (const tableName of tableNames) {
const [tableExists] = await dataset.table(tableName).exists();
if (tableExists) continue;
await dataset.createTable(tableName, {});
}既存の転送定義が存在する場合は、転送定義を削除する
次の既存の転送定義の有無を確認して、存在したら削除する処理を実装します。
// BigQuery Data Transfer Service のクライアントを初期化
const bqTransfer = new DataTransferServiceClient({ projectId: 'bigqeury-projectname-xxx',, authClient: client }); // clientは上で生成したもの
// 転送定義一覧を取得
const [configs] = await bqTransfer.listTransferConfigs({ parent: `projects/bigqeury-projectname-xxx/locations/asia-east2` });
// 転送定義が存在したら削除
for (const tableName of tableNames) { // この tableNames は上で取得したもの
const existingConfigs = configs.filter((c) => c.displayName === tableName);
for (const existingConfig of existingConfigs) {
await bqTransfer.deleteTransferConfig({ name: existingConfig.name }); // 転送定義name=テーブル名としてある
}
}転送定義を作成する
転送定義を作成します。
スケジュール実行にするとややこしいので、スケジューリングせず、オンデマンドで実行する設定で作成します。
設定値は、こちら で確認できます。
-
data_pathの部分は、パスのフォルダ構成をちゃんと指定しないと上手く認識してくれませんでした- ちなみに、このパスの部分は毎日異なるフォルダに出力されるため、最新のスナップショットが格納されているフォルダパスを取得する必要があります。この例では端折ってますが、実際にはS3から最新のスナップショットのパスを取得してそれを指定する必要があります
- この転送設定のオーナーはサービスアカウントになるため、転送実行時にエラーが発生した場合には、サービスアカウントのメールアドレスにメールが送信され、気づくことができません。他のメールアドレスをパラメータで設定してみたのですが、ダメでした。エラーを検知するためには、pub/sub で通知する必要あるようですが、今回はそこまでやってません。
const parent = bqTransfer.projectPath('bigqeury-projectname-xxx');
const configs = [];
for (const tableName of tableNames) {
const [config] = await bqTransfer.createTransferConfig({
parent,
transferConfig: {
name: tableName,
displayName: tableName,
destinationDatasetId: 'dataset-xxxx',
dataSourceId: 'amazon_s3',
scheduleOptions: { disableAutoScheduling: true }, // スケジュール実行はしない
params: {
fields: {
destination_table_name_template: { stringValue: tableName },
data_path: {
stringValue: 's3://xxxx-bucket/snapshot/xxxxxx/xxxxxx.${tableName}/*/*.parquet',
},
access_key_id: { stringValue: 'xxxxxx' },
secret_access_key: { stringValue: 'xxxxxx' },
file_format: { stringValue: 'PARQUET' },
write_disposition: { stringValue: 'WRITE_TRUNCATE' },
},
},
emailPreferences: { enableFailureEmail: true },
},
});
configs.push(config);
}転送を開始する
最後は、転送を開始する部分を実装します。
for (const config of configs) { // configs は上で取得
await bqTransfer.startManualTransferRuns({ parent: config.name, requestedRunTime: { seconds: new Date().getTime() / 1000 } });
}実行
上記で作成した Lambda を実行すると、 BigQuery の「データ転送」タブに新しい転送定義が作成されて、転送が開始されます。
実行時に以下のようなトラブルが発生したので、並列実行で対応しました。
- シーケンシャルに100以上のテーブルについて、テーブル作成=>転送定義削除=>転送定義作成=>転送開始をやったところ、Lambdaの実行時間の制限(15分)を超える可能性がありそうだった。実際、12分ぐらいかかっていた
- 単純に promise.all で一気に並列実行したら、GCP側の API コール回数の Quota に引っかかって途中でエラーになった
- => 3 並列ぐらいで処理するようにしたら、処理時間も5分ぐらいでおさまり、Quota エラーも出なくなった
トラブルは上記ぐらいで、問題なく動いてくれました。
最後に
今回、「RDSの自動スナップショット => S3にエクスポート => BigQuery Data Transerで BigQueryに転送」という構成でRDSをBigQueryに同期する仕組みを作りました。
一週間くらいは運用してますが、一度もエラーなく毎朝動いてくれています。
特に、スナップショットをインプットにしているので、
- 実運用中のDBに負荷がかからないこと
- データの断面が揃っていること
が気に入っています。
1日に一度程度の同期頻度で良い場合は、この構成結構いいんじゃないかなと思いました。