やりたいこと
候補ノード(約1億件)と候補同士のリレーション(約100億件)をneo4jに登録して、特定の条件で繋がっているサブグラフのノードIDを抽出したいと思います。
入力データ
候補1 -- 候補2 (score = 40)
候補1 -- 候補3 (score = 60)
候補3 -- 候補4 (score = 50)
候補4 -- 候補5 (score = 70)
候補6 -- 候補7 (score = 30)
候補7 -- 候補8 (score = 70)
候補9 ... リレーションなしscoreは関連性の強さです。本来、関連性に方向はありません。
グラフ表示するとこんなイメージです。
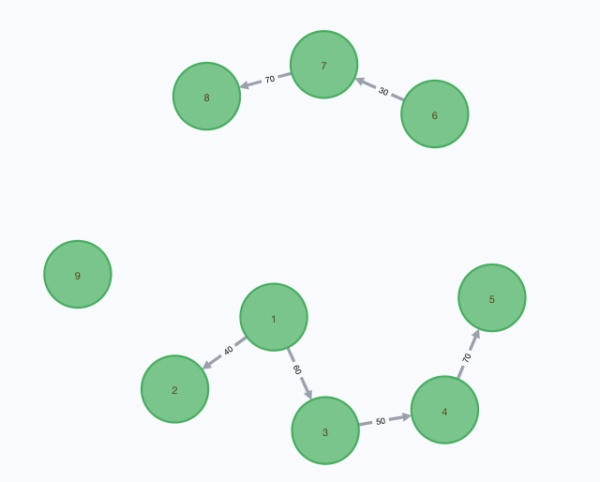
このデータからクエリでscore >= 50以上のリレーションを接合して、以下のようなデータを取得したいと思っています。
[候補1, 候補3, 候補4, 候補5]
[候補2]
[候補6]
[候補7, 候補8]
[候補9]なぜグラフDBを利用するのか
あるプロジェクトで[候補]と[候補同士の関連性]を元に候補を適切にグルーピングするということをやっています。これはまさにグラフのノードとエッジ(リレーション)に当たるのですが、他の多くの情報をBigQueryで管理しているので、このグラフデータもBigQueryで管理してきました。
サンプルデータだと[候補同士の関連性]が数10万件レベルで特に問題なく動いていたのですが、本番データだと[候補同士の関連性]の件数が100億件を超えることが分かり、現在のBigQueryから関連性情報をダウンロードしてバッチサーバ内で接合していく今のやり方では、数TB以上のメモリが必要なことが分かりました。
グラフDBであれば、BigQueryのSQLでは表現できなかったような、ノードを接合してグルーピングするような処理もDBサーバ内で実行できるので、バッチサーバ側のメモリの問題も解消できるはず、と思い、グラフDBを導入することにしました。
ちなみに、Google Cloud Bigtable + JanusGraphの組合せも少し考えましたが、情報が少なく初めて触るには不安があったので、情報が多くて安心感のあるNeo4jを利用することにしました。
Neo4jのインストール
brew でインストールする場合
/usr/local/Cellar/neo4j/3.5.14/libexec にインストールされます。
2020/03/06現在、v3.5.14がインストールされます。4系は無さそうです。
# インストール
brew install neo4j
# 起動
neo4j start
# 停止
neo4j stop
# ステータス確認
neo4j statusdocker-compose を利用する場合
docker-compose.yamlは以下のような感じです。
2020/03/06現在、v4.0.1のイメージがすでにdocker-hubに上がっています。
version: '3'
services:
neo4j:
image: neo4j:latest
ports:
- "7474:7474" # for HTTP
- "7687:7687" # for Bolt
volumes:
- ${HOME}/neo4j/data:/data
- ${HOME}/neo4j/logs:/logs
- ${HOME}/neo4j/conf:/conf
- ${HOME}/neo4j/import:/import # CSVインポートをする場合には必要# コンテナ起動(バックグラウンドで)
docker-compose up -d
# コンテナ停止
docker-compose stop
# コンテナ削除
docker-compose down管理画面表示
DBサーバを起動したら、以下のURLにアクセスします。
- user_name: neo4j
- password: neo4j
初期パスワードでログインし、パスワードを変更すると、管理画面が表示されます。
サンプルグラフでお試し
管理画面のメニューで Example Graphsに二つのサンプルが準備されています。
- Movie Graph
- Northwind Graph
画面上部のスクリプトエディタで
:play movie-graphを実行すると、Movie Graphの説明が数ページに渡って表示されます。
2ページ目にMovie、Personの二種類のノード、Movie-Person間のリレーションを作成するクエリが表示されるので、クリックしてエディタにコピーし、実行するとデータが作成されます。
3ページ目以降に登録したデータを検索するクエリサンプルがたくさんあるので、試してみると良いと思います。
サンプルデータ削除する
DETACHをつけることで、リレーションもまとめて削除してくれるようです。
MATCH (n) DETACH DELETE n管理画面でやりたいことを実現
いきなりpythonで実装するのではなく、まずは管理画面上のCypherクエリベースでやりたいことができるのかを確認してみます。
データ登録
ノードとリレーションを登録するクエリはこんな感じです。
実際にはノードが1 億件、リレーションが100億件ぐらいになる想定です。
CREATE (c1:Candidate {id:1})
CREATE (c2:Candidate {id:2})
CREATE (c3:Candidate {id:3})
CREATE (c4:Candidate {id:4})
CREATE (c5:Candidate {id:5})
CREATE (c6:Candidate {id:6})
CREATE (c7:Candidate {id:7})
CREATE (c8:Candidate {id:8})
CREATE (c9:Candidate {id:9})
CREATE
(c1)-[:RELATED {score: 40}]->(c2),
(c1)-[:RELATED {score: 60}]->(c3),
(c3)-[:RELATED {score: 50}]->(c4),
(c4)-[:RELATED {score: 70}]->(c5),
(c6)-[:RELATED {score: 30}]->(c7),
(c7)-[:RELATED {score: 70}]->(c8)ノードラベルCandidateは候補を表し、リレーションタイプRELATEDは関連があることを示しています。RELATEDのプロパティscoreは関連性の強さを格納しています。
Neo4jでは無向もしくは双方向のリレーションを作成することはできないので、一方向のリレーションを登録しておき、クエリで方向を無視(--)して検索することになります。
データ抽出
Cypherクエリで、scoreが50以上のリレーションを繋いで候補IDのリストを取得します。
MATCH (cs:Candidate)
OPTIONAL MATCH p = (cs)-[*]-(:Candidate) // リレーションがないものも抽出
WHERE all(r IN relationships(p) WHERE r.score>=50) // score50点以上で絞り込み
WITH
cs.id AS cs_id
, CASE WHEN p IS NULL THEN [cs.id] ELSE [n IN nodes(p)|n.id] END AS ids // リレーションがない or 50点未満の場合はpがnullになっている
UNWIND ids AS id
WITH cs_id, id
ORDER BY cs_id, id // もともとpath順になっているのでここでソート
WITH cs_id, collect(DISTINCT id) AS sorted_ids // 開始候補IDでグルーピング
RETURN DISTINCT sorted_ids // 重複を排除して返却無事、目的のデータを取得することができました。
// 実行結果
╒════════════╕
│"sorted_ids"│
╞════════════╡
│[1,3,4,5] │
│[2] │
│[6] │
│[7,8] │
│[9] │
└────────────┘ポイントをいくつか書いておきます。
- リレーションが繋がっていない候補も取得するために
OPTIONAL MATCHを使う - pathの途中に含まれる全てのノードを
nodes(p)で取得する - WHERE句でlistに対して絞り込みをする際は
all()を利用する - 各pathのノードリストの重複を排除するためにlistの要素をソートしたいが、直接ソートする方法がないので、一旦
UNWINDする
pythonでやりたいことを実現
Cypherクエリでやりたいことを実現することができたので、あとはpythonで実装するだけです。
neo4j-driverをインストール
2020/03/06時点で、python-driverはneo4j v4.0に対応してないと書いてありますが、今回の利用範囲では問題なく動きました。
pip install neo4j-driverNeo4jアクセス用のクライアントラッパーを作成
本記事としてはなくても全然いいのですが、実運用で使うにはラッパークラスを作っておいた方が使いやすいので、作りました。
from neo4j import GraphDatabase, Driver, StatementResult, TransactionError, Session, Transaction
import traceback
from typing import Dict, Any
class Neo4jClient:
driver: Driver
session: Session
transaction: Transaction
readonly: bool
with_transaction: bool
def __init__(
self,
uri: str = 'bolt://localhost:7687',
user: str = 'neo4j',
password: str = 'neo4j',
readonly: bool = True,
with_transaction: bool = True):
self.driver = GraphDatabase.driver(uri, auth=(user, password), encrypted=False)
self.session = self.driver.session()
self.readonly = readonly
self.with_transaction = with_transaction
self.transaction = self.session.begin_transaction() if self.with_transaction else None
def commit(self):
if self.readonly:
raise TransactionError('cannot commit when readonly')
if self.session.has_transaction():
self.transaction.commit()
def rollback(self):
if self.session.has_transaction():
self.transaction.rollback()
def run(self, query: str, **kwargs: Dict[str, Any]) -> StatementResult:
print(f'query: {query}')
print(f'kwargs: {kwargs}')
result: StatementResult
if self.with_transaction:
result = self.transaction.run(query, kwargs)
else:
result = self.session.run(query, kwargs)
return result
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, tb):
if tb is not None:
print(''.join(traceback.format_tb(tb)))
if self.session.has_transaction():
self.rollback()
self.session.close()
self.driver.close()使い方はこんな感じです。
# 参照系
with Neo4jClient() as client:
for row in client.run('MATCH (t:Test) RETURN t.id as id')
print(row[id])
# 更新系
with Neo4jClient(readonly=False) as client:
client.run('MATCH (t:Test) DETACH DELETE t')
client.run('CREATE (:Test {id:1})')
client.run('CREATE (:Test {id:2})')
if bussiness_check_ok():
client.commit()
else:
client.rollback()データをCSVロードで登録
実データは100億件ぐらいあるので、CSVロードで登録する方法を試しました。
import csv
import time
from typing import str
nodes_csv_name: str = 'nodes.csv'
relations_csv_name: str = 'relations.csv'
# ノード用CSVファイル書き込み
with open(f'{path_to_neo4j_dir}/import/{nodes_csv_name}', 'w') as f:
writer = csv.writer(f)
writer.writerow(['id'])
for i in range(1, 10):
writer.writerow([i])
# リレーション用CSVファイル書き込み
with open(f'{path_to_neo4j_dir}/import/{relations_csv_name}', 'w') as f:
writer = csv.writer(f)
writer.writerow(['from_id', 'to_id', 'score'])
writer.writerow([1, 2, 40])
writer.writerow([1, 3, 60])
writer.writerow([3, 4, 50])
writer.writerow([4, 5, 70])
writer.writerow([6, 7, 30])
writer.writerow([7, 8, 70])
# この待ちを入れないと、ごくたまに不完全なCSVファイルをロードして失敗する
time.sleep(0.1)
with Neo4jClient(with_transaction=False) as client:
# ノード用CSVデータをロード
nodes_query: str = """
USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM $csv_path AS line
CREATE (:Candidate {id:toInteger(line.id)})
"""
client.run(nodes_query, csv_path=f'file:///{nodes_csv_name}')
# リレーション用CSVデータをロード
relations_query: str = """
USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM $csv_path AS line
MATCH (cf:Candidate {id:toInteger(line.from_id)}), (ct:Candidate {id:toInteger(line.to_id)})
CREATE (cf)-[:RELATED {score: toFloat(line.score)}]->(ct)
"""
client.run(relations_query, csv_path=f'file:///{relations_csv_name}')ポイントは以下の点です。
- CSV LOAD機能はCypherクエリで実行するため、DBサーバ側で実行されます。そのためDBサーバのローカルファイルを読み込むか、HTTP/HTTPS/FTPでファイルを取得するか、になります。今回はWEBサーバを立てるのが面倒だったので、DBサーバ上のimport用フォルダ(デフォルトでは
{$NEO4J_HOME}/import)にCSVファイルを作成してロードしました。dockerを利用している場合、ホストマシンの適当なディレクトリをdockerコンテナ側の/importディレクトリにマウントする必要があります。 - 理由はよく分からないのですが、CSVファイルに書き込んで、そのまますぐにCSVロードすると、空の行がロードされてしまうことが稀にあり、苦肉の作で
time.sleep(0.1)を入れています - 大量データをロードする際のメモリ不足を回避するために、
USING PERIODIC COMMIT 10000を指定すると、指定した件数毎にまとめてcommitしてくれます。ただしこれはトランザクション内では実行できません - CSVから
LOAD CSVで読み込んだ値は文字列扱いになるので、intやfloatにしたい場合はtoInteger()やtoFloat()関数で変換する必要があります
実際のデータを取得
query: str = """
MATCH (cs:Candidate)
OPTIONAL MATCH p = (cs)-[*]-(:Candidate)
WHERE all(r IN relationships(p) WHERE r.score>=50)
WITH
cs.id AS cs_id
, CASE WHEN p IS NULL THEN [cs.id] ELSE [n IN nodes(p)|n.id] END AS ids
UNWIND ids AS id
WITH cs_id, id
ORDER BY cs_id, id
WITH cs_id, collect(DISTINCT id) AS sorted_ids
RETURN DISTINCT sorted_ids
"""
# 自作のラッパーを使用する場合
with Neo4jClient() as client:
for row in client.run(query):
print(row['sorted_ids'])
# 直接ドライバーを使用する場合
driver: Driver = GraphDatabase.driver('bolt://localhost:7687', auth=('neo4j', 'neo4j'), encrypted=False)
with driver.session() as session:
with session.begin_transaction() as tx:
for row in tx.run(query):
print(row['sorted_ids'])
# 出力結果
# > [1, 3, 4, 5]
# > [2]
# > [6]
# > [7, 8]
# > [9]無事、pythonでもやりたいことを実現できました。
感想
実際に初めてNeo4jを使ってみましたが、今回の範囲だと多少詰まることもあるけれど、公式マニュアルが充実していて、どこかに対応方法が書いてあるため、比較的すんなりやりたいことを実現できました。
今回は、リレーションのscore算出に使うメタデータの管理も、scoreの算出も全てBigQuery上で処理をしており、scoreを元にノードを繋ぐところだけにNeo4jを使っているのですが、本来全てをNeo4j上で管理、処理した方が構成上スッキリしたかもしれないと思いました。
あとは、実運用で数100億件のリレーションデータに本当に耐えられるのかが気になるところです。
後日談
実データでやる前に、15万ノード、3億リレーションで試してみたところ、実行時間がかかりすぎることが判明しました。数日間改善を試みたところ結局解決できず、Neo4j導入は一旦白紙に戻すことにしました。
ハマったこと①:CSVロードが意外に大変
まず、この記事で紹介したCSVロードの方法ですが低速で、データ量が3億件でも全く応答がありませんでした。こちらは別記事で対応方法を記載しましたので、詳細はそちらをご確認ください。
Neo4jにCSVロードする4つの方法
ハマったこと②:リレーション数が多いと結果が返ってこない
次に、15万ノード、3億リレーション内に含まれる特定条件のサブグラフを抽出する処理ですが、こちらも全く応答がありませんでした。
そちらはneo4jのコンサルティング会社の技術担当の方に相談したりもしたのですが、結局簡単には解決できる感じではなく、時間もなかったので一旦諦めましたww
その際に試したいくつかのチューニングについては、別記事で書こうかなと思っております。
TBD
[参考] メモリはどれぐらい使うか
ノード1億件、リレーション100億件ぐらいの想定なのですが、公式マニュアルに以下の記述がありました。
To avoid hitting disk you need more RAM. On a standard mechanical drive you can handle graphs with a few tens of millions of primitives (nodes, relationships and properties) with 2-3 GBs of RAM. A server with 8-16 GBs of RAM can handle graphs with hundreds of millions of primitives, and a good server with 16-64 GBs can handle billions of primitives. However, if you invest in a good SSD you will be able to handle much larger graphs on less RAM.
つまり、RAM 16-64 GB で数10億件を処理できるそうです。100GB積めばきっと大丈夫と信じたいところです。
[参考] Communityエディション or Enterpriseエディション
今回はCommunityエディションでなんとか大丈夫と判断しました。
こちらに二つのエディションの違いが書いてあります。特に気になったのは、以下二点です。
- Cluster
- Graph size limitations: 34B nodes
今回は、グラフのリレーションを繋ぐところだけをNeo4jで行って、結果データを恒久的に管理するのはあくまでBigQueryで行うことを考えているため、Clusteingできなくて大丈夫と判断しました。
ノード数(おそらくリレーション数も)が340億件の制限も、見積もり上はギリギリ収まるはずです。