最近Sparkを触る機会があって、少しだけ勉強したのでメモがてら残しておきます。
Sparkの分散処理の仕組み
Sparkとは
- 高速で汎用的な分散処理システム
- 分散データ(RDD)をDISKを介さずにメモリ上に持つので、Hadoopの100倍ぐらい高速
- Java, Scala, Python, RなどのAPIを提供
- Spark SQL, MLlib, GraphX, Spark Streamingなどのリッチなツールを提供
分散処理システムの構成要素
画像は、こちらからお借りしました。
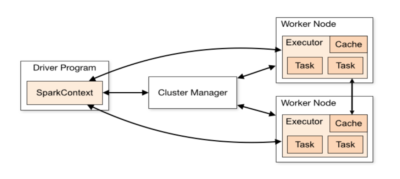
- Driver Program
- Master Nodeで実行される起点となるプログラム
- SparkContextを作成し、RDDを生成して、Taskを実行していく
- SparkContext
- Sparkの色々な機能へのエントリーポイント
- ClusterManagerを通じてクラスターを操作する
- DAG Scheduler: 一度に並列処理可能な範囲をStageに分割して、 Stage内は複数のTaskで構成する。それをDAG(有向非巡回グラフ)の形式で表現するのでDAG Schedulerというらしい。
- Task Scheduler: DAG Schedulerでスケジュールされた順番にTaskをCluster Managerにロンチする
- こちらのサイトがわかりやすかった
- ClusterManager
- アプリケーションを実行するために必要なリソースの割り当て渡ってきたTaskをExecuterに渡す
- Spark Standalone Cluster, Hadoop YARN, Apache Mesosなど
- Executor
- Worker Node上でJVMコンテナ起動されるアプリケーション専用のプロセス
- Taskを実行する。またCache Dataを保持する
処理の流れ
自分の理解では、以下のような処理の流れになっているみたいです。
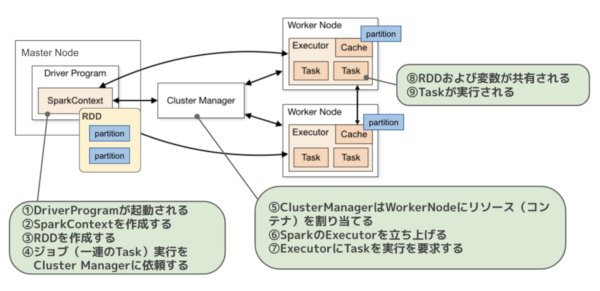
分散処理の実装サンプル
処理内容
試験の結果から「各教科の平均点」と「4教科合計の平均点」を算出するという比較的シンプルな処理を考えてみようと思います。
ソースコード
from pyspark import SparkContext, RDD
from typing import List, Dict
# inputデータ(試験の結果)
input_data: List[Dict[str, int]] = [
{'国語': 86, '算数': 57, '理科': 45, '社会': 100},
{'国語': 67, '算数': 12, '理科': 43, '社会': 54},
{'国語': 98, '算数': 98, '理科': 78, '社会': 69},
]
# SparkContext, RDD作成
sc: SparkContext = SparkContext(appName='spark_sample')
rdd: RDD = sc.parallelize(input_data)
# 各教科および合計点の平均点を計算
output: Dict[str, float] = rdd\
.map(lambda x: x.update(合計=sum(x.values())) or x)\
.flatMap(lambda x: x.items())\
.groupByKey()\
.map(lambda x: (x[0], round(sum(x[1]) / len(x[1]), 2)))\
.collect()解説
まず、SparkContextを生成しています。
sc: SparkContext = SparkContext(appName='spark_sample')前述の構成要素のところで説明したやつです。DAG SchedulerやTask Schedulerの役割を果たしてくれます。
次に、RDDを生成しています。
rdd: RDD = sc.parallelize(input_data)RDDは復元力のある分散データセットで、ただListを分割しただけでなく、いろんな特徴があります。
- Fault Tolerance: 失敗してもいい感じに復旧してくれる
- Immutable: 変換処理を行う場合は、必ず新しいRDDを作成する。元データが保持されているのでリトライができる
- Lazy Evaluation:
collectやforeachなどのActionと呼ばれるTaskが実行されるまで処理されない。Actionが実行されたタイミングで必要なTaskだけ実行される(=jobがsubmitされる)
などの特徴を持っています。
最後に、RDDに対して一連の変換タスク行い、結果を取得しています。
output: Dict[str, float] = rdd\
.map(lambda x: x.update(合計=sum(x.values())) or x)\
.flatMap(lambda x: x.items())\
.groupByKey()\
.map(lambda x: (x[0], round(sum(x[1]) / len(x[1]), 2)))\
.collect()具体的には、以下のような流れで処理を行なっています。
- 合計を各recordに追加
{ ‘国語’: 86, ‘算数’: 57, …, ‘合計’: 288 } - List[Tuple[教科, 点数]]に変換(縦持ちに)
[(‘国語’, 86), (‘算数’, 57), … , (‘合計’, 288)] - 教科でグルーピング
(‘国語’, [86, 67, 98]) - 平均点を算出
(‘国語’, 83.67) - 全recordを集約
[(‘国語’, 83.67), (‘算数’, 55.67), …, (‘合計’, 269.0)]
Stage構成はこんな感じです。
[f:id:rinoguchi:20200429125214p:plain:w500]
collectなどのAction Taskの他に、groupByKeyのようなShuffle TaskでもStageが分割されます。ByKeyで終わるようなTaskがShuffle Taskです。一つのStageの一連のTaskは一つのNodeで一括で処理されます。
分散処理の実行
これから3つの方法で先ほど実装した分散処理プログラム(main.py)を実行してみたいとも思います。プログラムはどの方法でも変更の必要はありません。
pysparkライブラリを使って実行
実行方法
# 必要なライブラリをインストール
pip install pyspark
pip install py4j
# 実行
python main.py特徴
- 通常のpythonアプリと全く同様に実行することができてお手軽
- クラスタ準備不要
- アプリの動作確認はほとんどこれでいいと思う
- 実運用では使えない
Spark Standalone Modeで実行
実行方法
# apache-sparkをインストール
brew install apache-spark
export SPARK_HOME=/usr/local/Cellar/apache-spark/2.4.5/libexec
# Master Nodeを立ち上げる
# 立ち上げた後に、http://localhost:8080にアクセスして、Master-URLを確認する
# 例) spark://hogeMacBook-Pro:7077
${SPARK_HOME}/sbin/start-master.sh
# Worker Nodeを立ち上げる
${SPARK_HOME}/sbin/start-slave.sh -c 2 spark://InoguchinoMacBook-Pro:7077
# jobをsubmitする
spark-submit main.py --master spark://InoguchinoMacBook-Pro:7077特徴
- ローカルマシン上にクラスタ(master & workers)を構築して、クラスタ上でジョブを実行させるため、クラスタを準備する必要がある
- いくつかのコマンドを打つ必要があり多少手間
- SparkUIで、Event Timelineを確認したり、DAG(タスクの流れを表した有向非循環グラフ)を確認できるので、性能改善の用途で使う
- 実運用では使う意味はなさそう
- 同一マシン内でマルチコアで並列処理したいだけなら、
concurrent.futuresとかでもできるので
- 同一マシン内でマルチコアで並列処理したいだけなら、
Google Cloud Dataprocで実行
Dataprocの環境準備
こちらの「Dataproc周りの環境準備」の項を参照し、Dataprocを有効化してサービスアカウントを作成し必要な権限を与えます。
実行方法
# サービスアカウントを有効化
gcloud auth activate-service-account --key-file {key_file_json_path} --project {project_name}
# クラスタ立ち上げ
gcloud dataproc clusters create spark-sample-cluster\
--bucket={bucket_name} --region=asia-east1 --image-version=1.4\
--master-machine-type=n1-standard-1 --worker-machine-type=n1-standard-1\
--num-workers=2 --worker-boot-disk-size=256 --max-idle=1h
# jobをsubmit
gcloud dataproc jobs submit pyspark\
--cluster=spark-sample-cluster --region=asia-east1\
gs://hoge_dataproc-test/dataproc/src/simple/main.py特徴
- DataprocはGoogleが提供するフルマネージドな分散処理クラウドサービス
- クラスタ(master & workers)を素人でも簡単に作れる
- コンソール画面、CLI、各言語のドライバーから、手軽にクラスタを作成したり、JOBを実行したりできる
- 1vCPU × 1hour = 1セント = 0.01ドル
まとめ
個人的には、
- まずpysparkライブラリで実装・動作確認のイテレーションを行い
- Spark Standalone Modeで軽くDAG Scheduleや各Taskの実行時間を確認した上で
- 最終的にDataprocで本番運用する
という流れで開発を行いましたが、これは結構しっくりきました。