これは ドメイン駆動設計 Advent Calendar 2020 の16日目の記事です。
「実践ドメイン駆動設計」から学ぶDDDの実装入門 を輪読会で読了したので、内容を箇条書きでメモしておきます。
個人的解釈を多分に含むため、導入する際には実際に書籍を読んで判断してもらえればと思います。
1. 「DDDへの誘い」〜ドメイン駆動設計のメリットと始め方〜
DDDとは
- DDDとは
- 「高品質」のソフトウェアを設計する手法
- 「高品質」とは、ビジネス的にも成功していること言うこと
- 「事業を理解し、チームの知識を一つにまとめること」を重視し、「ユビキタス言語」というチーム内の共通語でプログラムを実装する
- DDDのメリット
- プログラマとドメインエキスパートが「共通言語」で視点を合わせて会話する=>顧客視点に繋がる
- チームで業務知識を共有し、理想像を追求できる
- 「設計=コード」を実現し、実装時の課題を設計段階で気づける
- ドメインエキスパートとは
- その事業やシステムについて、肩書き関係なく一番理解している人
- ドメインモデルとは
- 複雑な(細々した)業務領域を抽象化して、システムやサービスに必要な概念を抽出したもの
DDD導入の可否
- 導入した方がよい
- ビジネスロジックが複雑なケース
- 計算処理・妥当性チェックのようなビジネスロジックを一元管理する
- UIやリクエストに依存しないため、シンプルに考えられる
- ビジネスロジックが複雑なケース
- 導入しない方がよい
- ビジネスロジックが複雑でないケース
- 単純なマスタメンテナンス
- 30程度のユースケース
- ビジネスロジックが複雑でないケース
ユビキタス言語
- ユビキタス言語とは
- チーム全体で作り上げる特別な共有言語
- ユビキタス言語の見つけ方
- ドメインに登場する用語+アクションを列挙する
- 列挙が難しければ、既存ドキュメントからそれっぽいのを抜き出す
- 用語集(=共通言語、ユビキタス言語)として残すか「採用/却下理由」を書いていく
- ドメインに登場する用語+アクションを列挙する
- アクションとは
- 振る舞いのこと
- 用語「給与」は、アクション「社員の勤続年数を元に計算される」をもつ
- ユビキタス言語の実装
- 「給与」が「社員の勤続年数を元に給与を計算する」のであれば、「社員」モデルが「勤続年数」というプロパティを持ち、「給与」モデルが「社員」プロパティを持ち、「給与を計算する」と言う関数を持つ事になる
DDD導入に向けて
- 説得方法
- 色々書いてあるけどうまく説得できる気がしなかった
- みんなで一緒にDDDを勉強して、みんなその気になったら導入するみたいな感じが良さそう
- 導入の優先順位
- 重要な順番に適用していく
- コアドメイン => 汎用サブドメイン => 支援サブドメイン
Evans氏によるDDDの原則
- コアドメインに集中すること
- ドメインの実践者とソフトウェアの実践者による創造的な共同作業を通じて、モデルを探求すること
- 明示的な協会づけられたコンテキストの内部で、ユビキタス言語を語ること
2. 「ドメイン」「サブドメイン」「境界づけられたコンテキスト」 〜DDDで取り組む領域〜
問題領域
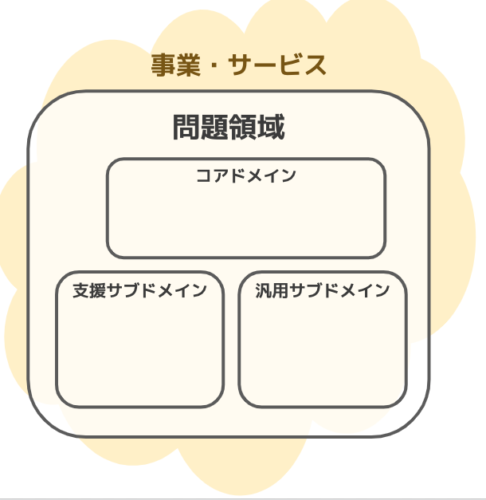
- 問題領域は、事業・サービスを分析し、課題・要件を明確化していく領域
- ここではどのように解決するかは考えず、純粋に課題に向き合う
解決領域
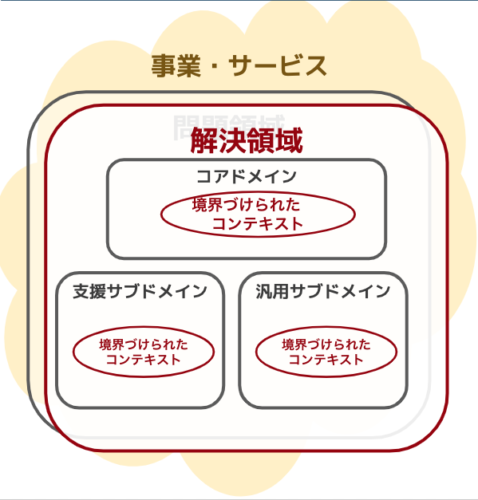
- ある事業・サービスについて、問題領域で見つかった課題を、主に技術的なソリューションを用いて解決する方法を検討する領域
- 解決領域は、問題領域の上にオーバーラップするイメージ
- 境界づけられたコンテキスト
- 解決領域には、境界づけられたコンテキストが存在する
- 一つのコアドメイン・サブドメインには基本的に一つの境界づけられたコンテキストが紐づく
- ちなみに、コンテキストは日本語だと「文脈」なのだが、その文脈の中で通用する最適化していけばいい(スコープを小さくすることで複雑さに対処する)
問題領域と解決領域
問題領域と課題領域がいまいちしっくりこなかったのだが、結局は、同じ事業・サービスに対して、
- 問題領域で、課題の分析・明確化(WHY・WHAT)する
- 解決領域で、ソリューションの検討(HOW)する
というように、課題とソリューションを切り分けて、別々に分けて考えましょうということを言っているだけのような気がしている
ドメイン
- ドメインとは
- 問題領域の中で、事業が取り扱う世界を抽象化したもの
- コアドメイン・サブドメインのように複数のドメインに切り分けで優先順位を明確にして取り組んでいく
- それぞれのドメイン内に集中して問題を分析/明確化していく中で独自のユビキタス言語(DSL・方言)を育てていく
- コアドメイン
- 事業を成功に導くためにもっとも重要なもの(例えば、cookpadなら、わかりやすくレシピを提供する、とか?)
- サブドメイン
- 汎用サブドメイン
- 業務的には特別でないが全体に必要なもの(認証系、外部ERP。差し替え可能)
- 支援サブドメイン
- 業務的には特別だが、重要ではない
- 汎用サブドメイン
3. 「コンテキストマップ」〜境界づけられたコンテキスト間のチーム関係〜
コンテキストマップ
- コンテキストマップとは
- コンテキスト間の関係性を一目で確認できる地図
- 書く理由
- 他のコンテキスト(チーム・システム)との連携方法を把握できる
- 組織間の問題を見つける唯一の方法 => 通常はコンテキスト内に集中しているため
- 書くタイミング
- なるべく早く
- 共有場所
- みんなが見れる場所に掲示 => ホワイトボード、チームWikiトップページとか
- 書き方
- ユビキタス言語が最適かを確認 => 一つの用語が複数の意味を持たないようにする
- 異なる概念が一つのコンテキストに入ってないか確認
- 関係性を組織的パターン・統合パターンで表す
組織的パターン
コンテキスト同士の関係性を、コンテキストを担当するチーム同士の関係性で表現するパターン
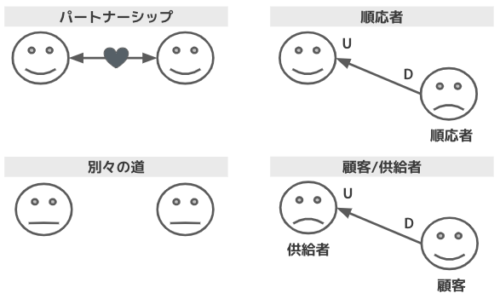
- パートナーシップ
- チーム間に協力関係あり
- 計画から連携テストまで共同でマネジメント
- 例)社内の業務プロダクトチーム同士など
- 別々の道
- 連携するメリットがない場合に、明確に統合しないことを示す
- 例)業務・機能が交わらないプロダクトや統合すると逆に大変なレガシーシステムなど
- 順応者
- 上流が下流の要望を考慮する必要がない
- 下流チームが腐敗防止層を設けて、上流側モデルを自モデルに変換する
- 例)認証/Pub・Sub基盤/メッセージ基盤など
- 顧客/供給者
- 上流が供給者、下流が顧客になるような関係
- 上流チームが下流チームを確実にサポート
- 例)スマホアプリ開発では、APIチームが上流、アプリチームが下流らしい
統合パターン
コンテキスト同士の関係性を、コンテキスト間の連携方法(技術的なソリューション)を示すパターン
共有カーネル
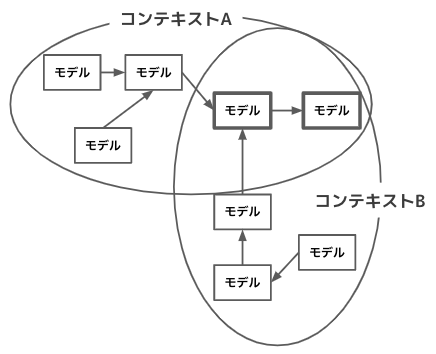
- 複数ドメインでモデルの共有が必要が場合に、変換層を設けてモデルの独立性を保つのではなく、ソースコードレベルで共有する方法
- 継続的に整合性をチェックし続ける必要があり、両チームでCI必要
- 変更には他チームの承認が必要なので、極力小さくする
- 例)例えばBigQueryのクライアントライブラリ、同一リポジトリで管理する別ドメインの共有フォルダ、DBスキーマなど
巨大な泥団子
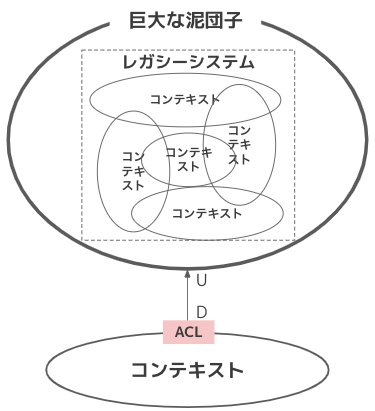
- DDDでは既存システムも適切な粒度のコンテキストに分けて管理するが、長年メンテされ続け肥大化したシステムは、無理にコンテキスト分割するのは諦め、巨大なコンテキストとして扱う
- 巨大な泥団子の古いモデルが自コンテキストに侵食する(レガシーシステムのモデルをそのまま利用する)ことを避けるため、通常「腐敗防止層(ACL)」をおいてモデルの変換を行う
公開ホストサービス(OHS)・公表された言語
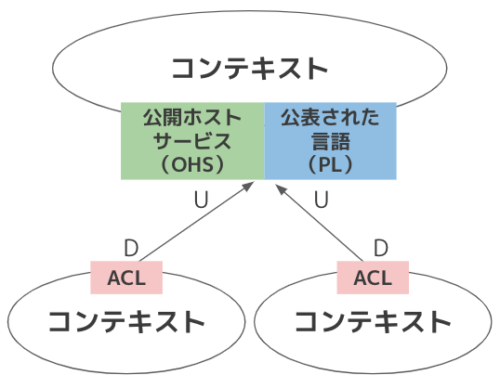
- 公開ホストサービス(OHS)
- コンテキストの内容(モデル)にアクセスできる公開サービス
- WEBサービス(REST API)が主流
- 公表された言語(PL)
- モデルの内容を変換するためには両者が理解できる共通言語が必要
- (Java同士とかならそのまま受け渡してもいいけど、)どんなプログラミング言語でも扱えるJSONやXMLを使うことが多い
- 最近だとprotocol bufferとかも
- OHSとセットで使われることが多い
腐敗防止層(ACL)
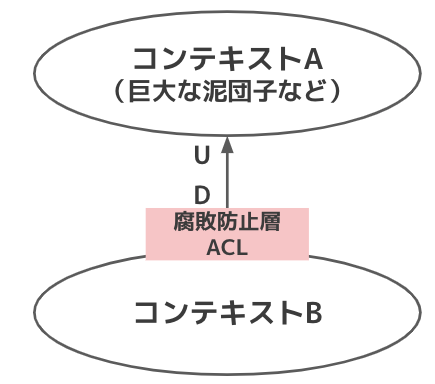
- 依存先のモデルが腐敗している場合、それをそのまま利用したくないので、間に変換層を噛ませる。その変換層を腐敗防止層と呼ぶ
- リクエスト送信して受診する一連の処理を考えると、双方向の変換が必要
- レイヤードアーキテクチャだと実態としてはリポジトリインターフェースをドメイン層におき、リポジトリ実装をインフラストラクチャ層に置くことが多いと思うが、このリポジトリ実装を腐敗防止層とすることが多い気がする
組織的パターンと統合パターン
コンテキストマップを書く時、どちらを用いても良いし、両方用いてもいいのだと思われる。両方用いると以下のような感じ。口の形だけで、順応者、顧客/供給者を見分けるのは結構厳しい...
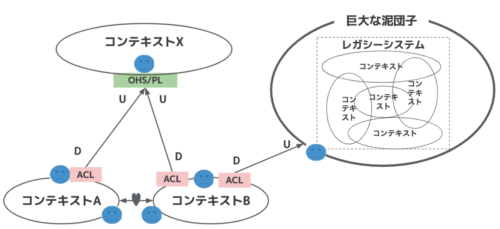
コンテキストに統合方式例
- 他のコンテキストに依存しない設計
- DDDでは、他のコンテキストへの依存性を下げるため、非同期処理をよく使う
- =>同期:整合性は保てるが、エラー発生や性能をコントロールしにくい
- =>非同期:自コンテキスト内で完結するので、エラー発生や性能はコントロールしやすいが、整合性を保つのが難しい
- DDDでは、他のコンテキストへの依存性を下げるため、非同期処理をよく使う
- リアルタイム性よりも「結果整合性」を重視
- ミッションクリティカルでもなければ、リアルタイム性はそれほど重要じゃない。一時的に不整合でも最終的に状態の整合性が取れてればOK=>結果整合性
- 実現方法
- イベント駆動(publisher: 回答あり、subscriber: ポイント付与)
- => publishされたイベントに対してきちんとsubscriberがリトライ含めて処理
- 定期的に整合性チェック+不整合の修正処理を実行
- イベント駆動(publisher: 回答あり、subscriber: ポイント付与)
4. 「アーキテクチャ」〜レイヤからヘキサゴナルへ〜
DDDのアーキテクチャにおいて特定の制約は存在しないので、機能要求(ユースケース、ユーザーストーリー、ドメインモデルのシナリオ)、品質要求(性能、エラー制御、SLA、リアルタイム性)を考慮して最適なアーキテクチャを選定すればよい。
レイヤードアーキテクチャ
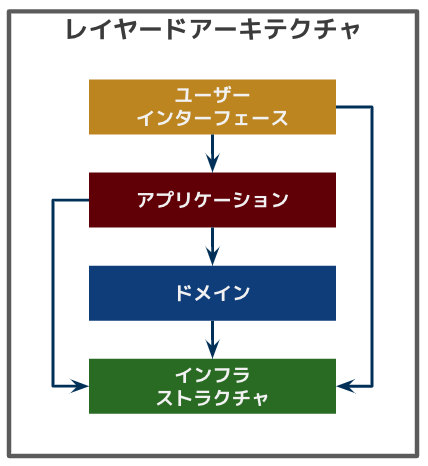
レイヤーの責務を明確にし、なるべく依存方向を1方向にするアーキテクチャ。
- ユーザインターフェース層
- 責務: 描画に必要なプレゼンテーション用のモデルにデータを設定する
- アプリケーション層
- 責務: ドメインロジックを持たずにコーディネートに徹する
- ドメイン層
- 責務: ドメインロジック(ユースケースやストーリー)を実現する
- インフラストラクチャ層
- 責務: リポジトリを使用してデータの永続化を行う
リポジトリを利用する層がインフラ層に依存してしまうため、基盤技術を変更した場合にその層が影響を受けてしまう点が問題。
ちなみに、ドメイン層がインフラ層に依存する図になってるが、アプリケーション側で依存を吸収することでドメイン層を独立させることは可能だと思う(アプリケーション層からリポジトリを呼び出して、ドメインのモデルに詰め替えて、ドメイン層はアプリケーション層から渡ってきたドメインモデルを処理する)。
レイヤードアーキテクチャ with DIP
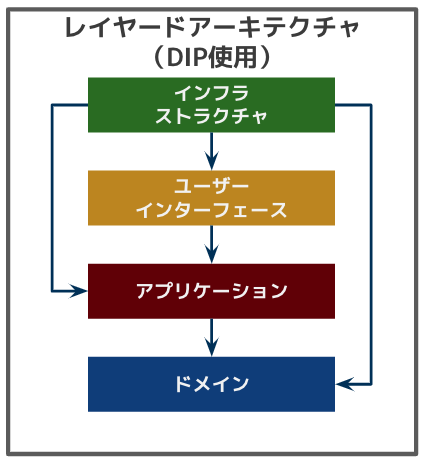
- DIPとは依存性逆転の法則のこと
- 直接リポジトリの実装に依存するのではなく、抽象(インターフェース)を内側の層(ドメイン)に配置してその抽象に依存することでインフラ層への依存がなくなり、インフラ層を外側に追いやることができる
- 前の図と比べるとインフラストラクチャ層が外側(上)に追いやられてることがわかる
- リポジトリを利用する層はドメインに依存している
ヘキサゴナルアーキテクチャ
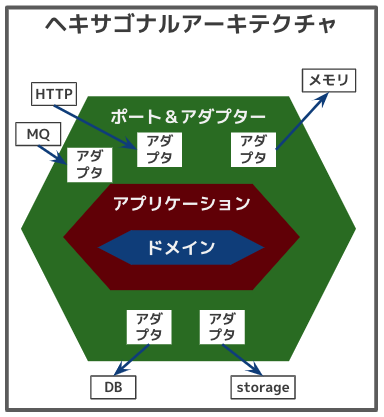
- ドメイン層およびアプリケーション層を中心に据え、入力側(画面からのユーザ入力、MQからのイベント、自動テスト)および出力側(DBへの永続化、ストレージへの書き込み)も差し替え可能なものと考えるアーキテクチャ
- 「ポート」は役割や目的に応じて定義され、一つのポートに対して複数の技術的に差し替え可能な「アダプタ」を実装する
- 例えば、「天気予報を送る」というポートを定義したとして、アダプターは「Web画面で表示する」「スマホアプリで表示する」「メールで送る」「SMSで送る」・・・など色々と考えられる
- しかし、「天気を予測して予報を作成する」というドメインはどのアダプターを採用しようと影響を受けない
ヘキサゴナルでのサービス指向アーキテクチャ(SOA)
ヘキサゴナルアーキテクチャで公開するサービスはSOAを意識するのが良いらしい。
ここでいうサービスとは、3章で紹介されていた「公開ホストサービス」のことだと思われる(たぶん)。
で、公開ホストサービスはREST APIが主流なので、REST APIで公開するサービスの設計指針と捉えて良さそう。
| no | 原則 | 説明 |
|---|---|---|
| 1 | 標準化 | サービスの説明をインターフェースで示す |
| 2 | 疎結合性 | 依存関係を減らし、サービス自身の依存情報を認識する |
| 3 | 抽象性 | インターフェースのみ公開し、内部実装は見せない |
| 4 | 再利用性 | 他のサービスから再利用できる |
| 5 | 自律性 | サービスが一貫性と信頼性を持ち、独立して成立する |
| 6 | ステートレス性 | サービスの利用者側で状態は管理し、サービス自体は状態を持たない |
| 7 | 発見可能性 | サービスの情報をメタデータで記述し、他から発見できる |
| 8 | 構成可能性 | 粒度の大きいサービスに組み込み可能で、制限がない |
(ほとんどは普遍的に良いとされる設計指針だと思うので、この文脈じゃなくても常に意識して良さそう)
CQRS(Command Query Responsibility Segregation)
- CQRSとは、Commandとクエリを分離しましょうという考え方
- Commandは、データを更新する処理。値は返却しない(型はvoid)
- Queryは、データを更新せず参照だけ行う処理
- なぜCQRSが必要?
- 参照系の処理はDDDと相性が悪いため
- 例えば、複数のテーブルから取得したデータを一覧表示したいだけの場合、以下のような大変な操作を行う必要がある
- それぞれのテーブルからリポジトリを通じて集約内のドメインオブジェクトを生成する
- ドメインサービスで複数の集約にまたがるドメインオブジェクトをまとめる
- UI用のモデルに詰め替える
- しかも性能が悪い
- 導入の仕方
- 既存の処理を単純にこれはCommand、これはQuery、、という感じに分けるのではダメ
- 例えば、「天気予報を作成して結果を表示する」という一連の処理があったとするとこれを二つに分ける必要がある
- Command: 天気予報を作成してDBに登録する(ここはDDDに準拠)
- Query: DBから天気予報を取得し、専用のモデルに詰めて返却する
- CommandとQueryを繋ぐには?
- イベント駆動アーキテクチャが必要?
- Command側で更新完了イベントを発行して、Query側はそのイベントをトリガーに処理を行う
- ブラウザ側で更新処理とは別に、取得処理をリクエストしても良さそう
- イベント駆動アーキテクチャが必要?
5. 「エンティティ」〜一意な識別子で同一性を識別〜
エンティティと値オブジェクトの違い
- エンティティ
- プロパティ値が変更されても同一と判断する必要がある
- IDがある。IDで同一性を識別する
- 例えば、ユーザエンティティはユーザーIDで同一性を識別し、姓名やメールアドレスが変わっても別人扱いにはしない
- 値オブジェクト
- プロパティ値が変更されたら別と判断する
- IDがない。プロパティ値そのもので同一性を識別する
- 例えば、カラー値オブジェクトは「RED」「YELLOW」などの値そのもので同一性を識別する
- 共通点
- どちらも、データと処理(振る舞い)の両方を持っている
- どちらも、ドメインオブジェクト(ドメインモデル)の一形態である
ドメインモデル貧血症
エンティティや値オブジェクトのようなドメインモデルが、DB項目をプロパティとして持つだけで、振る舞いを持たない状態のこと。DDDではオブジェクト指向のように、ドメインモデルがデータと振る舞いの両方を持ち、その中で自立して処理することが良いとされている。
ドメインモデル貧血症だと、ドメインモデルに対する処理を別で実装する必要があり(例えばドメインサービスやアプリケーションサービスなど)、凝集度が低くなり、密結合になってしまう。
エンティティの検討
- DBありきで検討するのではなく、ソフトウェアの要件からモデリングする
- 例えば、1テーブル = 1エンティティとするのはNG
- 要件(ユースケース)の主語と動詞に注目して、「主語」がエンティティになることが多く、「動詞」が振る舞いになることが多い
- エンティティのIDは値オブジェクトとして設計し、他の集約からの参照はIDのみとする
IDの生成タイミング
- 早期
- オブジェクト生成時に生成。例えばUUIDなど他と重複しない値を利用する
- 値に意味を持たせられないので、視認性が落ちる
- 遅延
- オブジェクト保存時に生成。例えばDBのシークエンスを利用する
- オブジェクト生成時点でIDが存在しないので、色々と不都合が出る
6.「値オブジェクト」〜振る舞いを持つ不変なオブジェクト〜
値オブジェクトの特徴
| 特徴 | 説明 |
|---|---|
| 計測/定量化/説明 | ドメイン内の知識を説明する |
| 不変 | インスタンス生成後は値は変更しない |
| 概念的な統一体 | 複数のプロパティの組合せで同一性が表現される |
| 交換可能性 | 値を変えたい場合は、オブジェクト全体を交換する |
| 等価性 | 値が等しいかどうかで比較できる |
| 副作用がない | 何回呼び出そうが、状態が不変 |
値オブジェクト or Stringやプリミティブ型
- Stringやプリミティブ型の不都合
- オブジェクト自身が複数のプロパティを組合せ管理できない
- 例えば、氏名とふりがなを同時に持てないし、姓と名を別々で管理することもできない
- オブジェクト自体が特別な振る舞いを持つことができない
- 例えば、郵便番号から都道府県を取得する振る舞いを持たせることもできない
- オブジェクトが自分自身の不変条件を定義できない
- 結果として処理開始時点のバリデーションに全て頼る形になり、どこかで値が変更されてないかを気にしながら利用する必要がある
- 例えば、電話番号は「数値」と「-」を含む10〜11桁の文字列という不変条件を担保したい
- オブジェクト自身が複数のプロパティを組合せ管理できない
- 値オブジェクトは上記の不都合を解決できる
- なので上記のようなケースでは、値オブジェクトを利用すると良さそう
- とはいえ「3.」のケースを言い出すとなんでも値オブジェクトにしなくてはいけない気がするのでどこまでやるかは検討が必要
列挙型(enum) or 値オブジェクト
- 列挙型も値オブジェクトの一種と思っていたが、別物っぽい書き方がされている
- 取りうる値が決まっている「区分」や「種類」を表すオブジェクトは、列挙型(enum)で実装する
- 取りうる値が決まってない場合は、値オブジェクトで実装する
7.「ドメインサービス」〜複数の物を扱うビジネスルール〜
DDDにおけるサービスとは
- ドメインサービス
- エンティティや値オブジェクトの責務ではないドメインモデルのロジック
- 複数の集約にまたがるオブジェクトを使って計算する処理など
- アプリケーションサービス
- とても薄く、ドメインモデル上のタスクの調整に使うロジック
- ドメインモデルのロジックを
- 腐敗防止層の変換、アダプター、トランザクション、セキュリティなど
ドメインサービスの失敗例
- 多用 / 誤用
- ドメインオブジェクトに実装すべきものを、ドメインサービスに実装すると、ドメインモデル貧血症になる
- ミニレイヤの提供
- 「ドメインサービス層」を常に作ってしまって、ドメインサービスからドメインオブジェクトを必ず呼び出すようなことをやると、ドメインレイヤが肥大化するし、無駄な実装も増える
- アプリケーションサービスでの実装
- ドメインサービスで実装すべきものをアプリケーションサービスで実装してしまうケース
- アプリケーション層は、トランザクションやセキュリティなどドメインの外側の関心事を実装する場所で業務ロジックを実装してはならない
ドメインサービス導入時のポイント
- リファクタリングによるドメインサービス導入
- 最初からドメインサービス有りきではなく、必要が出てきたら導入するのが良い(ミニレイヤや多用/誤用を防ぐ)
- 別の集約を利用しだしたら、ドメインサービスに切り出すのが良さそう
- 別の集約オブジェクトを取得する=他のリポジトリを呼び出す になるが、それは推奨されない
- 単一責任の原則(SRP原則)
- クラスの変更の理由が一つ以上存在してはならない
- 良い抽象には良い名前がつく
8.「ドメインイベント」〜出来事を記録して活用〜
ドメインイベント
- ドメインイベントはドメインモデルの一部であり、ドメインで起こった出来事を表す
- 何かのアクションのキッカケになる出来事
- 例) 「ユーザが登録された」「回答が登録された」「初めて画面を開いた」
- メリット
- 集約の制約から解放される(トランザクション範囲を広げずに結果整合性を保てる)
- バッチ処理がシンプルになる(例えば前日の更新データを複雑なSQLで取得する必要がなくなり、変更イベントをシンプルに受け取れる)
Pub/Sub
- パブリッシャー
- 集約の中でイベントを発行する
- サブスクライバー: イベントを購読する
- 同期処理
- イベントストア(キュー)にイベントを格納したりせず、同一トランザクションで直接サブスクライバを呼び出す
- イベント格納処理
- イベントストア(キュー)にイベントを格納し、非同期でサブスクライバがイベントを補足して処理を行う
- 分散処理
- イベントを他システムに送信して、分散処理を行う(?)
- 同期処理
イベントストア
- 発生したイベントの履歴をストレージに記録する方法
- メリット
- イベントのキューとして利用できる
- イベント履歴を、調査・監査・分析に使える
- イベントソーシングを実現できる
- イベントソーシングとは「イベントを元にデータを構築する」方法
- 「500円入金」「300円出金」といったイベントから残高=200円を導出
- 現在の状態(残高=200円)を直接管理しない
- 実例: GitやREDOログなど
- メリット
- 過去時点を復元できる
- デメリット
- データが膨大になる
- 計算処理が大変
- データ欠損に弱い
- バージョンアップ(イベントの内容変更)に弱い
- イベントソーシングとは「イベントを元にデータを構築する」方法
- 自立型のサービスにできる
- 他のサービス(API/RPCなど)をリアルタイムで呼び出すと、他サービスの状態に影響を受ける
- 他サービスから自サービスをポーリングしてもらう作りにすることで、独立性を担保できる
- イベントストアの実装
- RDBやNoSQLなど
- メッセージングミドルウェアのActiveMQ、RabbitMQ、Akka、NServiceBusなど
- クラウドサービス(GCP、AWS、Asureなど)のイベント送受信、キュー機能など
- サブスクライバ側の注意点
- イベントが重複する可能性があるので、同じイベントを複数回処理しても大丈夫な実装にする
9.「モジュール」〜高凝集で疎結合にまとめる〜
モジュール
- モジュール
- 「パッケージ」や「名前空間」に相当するもの
- 凝集度
- モジュールのまとまり具合に関する指標
- 関連性の強いクラスを一つのパッケージや名前空間にまとめる
- 高いほど好ましい
- 結合度
- 呼び出し関係にあるモジュール同士の結び付きの強さ
- 低いほど好ましい
- 必要な機能がまとまっていれば、外部モジュールと連携する必要がないので、結合度は低くなる
設計指針
- モデリングの概念にフィットさせる(例:集約=モジュール)
- モジュール名にはユビキタス言語に従う
- クラスの型や役割で機械的に決めるようなことはしない
- 疎結合に他のモジュールに依存しない(呼び出さない)
- 循環参照が起きないように。単一方向が望ましい
- 後からそぐわないことがわかったらリファクタリングする
モジュールの命名規約
- 重要なサブモジュール
-
infrastructure、domainなどのレイヤーレベル - ここには直接クラスを配置しない
-
- domainの下にはコンセプト名のモジュールをおく
-
domain.products、domain.tenantsなど -
serviceというモジュール名は悪手。これをやるとドメインロジック欠乏症になりがち
-
10. 「集約」〜トランザクション整合性を保つ境界〜
集約
- 集約とは
- ドメインオブジェクト(エンティティや値オブジェクト)を複数まとめたたもの
- トランザクション整合性を保つ必要があるオブジェクトのまとまり
- 集約ルート
- 外部から参照・操作できる
- => 逆に集約ルート以外は直接外部から参照・操作できない
- 集約全体のビジネスルールである不変条件を守る責務を保つ
- 集約ルートのエンティティは、グローバルで一意
- 集約内部のエンティティは集約内で一意となる
- 外部から参照・操作できる
- 境界
- 集約はトランザクション整合性を保つべき境界を示す
- 特定のDBのトランザクション命令ではない
- 集約本人がトランザクションをコントロールするという意味ではない
- 「登録する」「変更する」などのメソッドを呼び出した際に、一連の処理の途中状態を返したりせず、処理が完了した状態(永続化して良い状態)で返すという意味だと思われる
大きな集約と小さな集約
- 大きな集約
- ちゃんと考えない(安全側に倒しすぎると)と集約は大きくなる
- 大きくなると内包するオブジェクトが増えて、問題が発生する
- 問題点
- 性能低下
- 大量のオブジェクトを毎回メモリにロード
- 楽観ロックエラーが頻発
- 複雑
- 不変条件で気にしなくてはいけない範囲が広すぎ
- 性能低下
- 小さな集約
- 設計を工夫して集約を小さく分割する
- 他の集約はIDで参照する(実体を持たない)
- メリット(大きな集約の問題点の裏返し)
- 性能向上
- メモリにロードするデータが少ない
- 楽観ロックエラーの頻度が下がる
- スケーラビリティも上がる
- 一つ一つの処理がリソースを使わない
- 衝突しないので同時実行数も増やせる
- 集約の中がシンプル
- 性能向上
集約設計のポイント
- 小さな集約を設計する
- 理由
- 楽観ロックエラーを減らす、性能向上、スケーラビリティ向上
- 理由
- 極力、値オブジェクト(IDなし、変更管理なし、値だけで同一性判断)から構成する
- 理由
- シンプルになるから
- 理由
- 真の不変条件(ビジネスルール)を整合性の中にモデリングする
- 理由
- 集約の中は必ずビジネスルールを満たしているという前提で、利用者が利用できる
- 整合性を保つための実装が集約ルートに集約される
- 不変条件とは
- データが変更される時は常に維持されなければならない一貫性のルール
- 1つの集約内で適用されるルールは、トランザクションの完了によって強制される
- ルールとは、計算途中はともかく、最後に各プロパティの値が満たすべきデータの状態
- 例)合計=小計+消費税
- 例)配送先が国外の場合は、電話番号に国コードが入っている
- 集約ルートのエンティティが、不変条件を守ることに責任を持つ
- 集約をまたぐ不変条件はなるべく作らない
- 不変条件の範囲を集約として設計すれば、発生しにくくなる
- 大きくなりすぎる時は、集約をまたいで結果整合性を用いる
- 理由
- 他の集約への参照は、その一意な識別子(ID)を使用する
- 理由
- 疎結合にするため
- 本質的に他の集約の内部の情報は必要ないはず
- 他の集約が更新されていると、不整合が起こりうる
- 理由
- 境界の外部では結果整合性を用いる
- 理由
- トランザクション整合性を用いると集約が大きくなってしまうため
- メイン集約の結果を待って他の集約の更新を行いたい場合
- メイン集約でイベントを発生させて、他の集約はそれをサブスクリプトして処理する
- 集約間でそれぞれ更新していい場合
ドメインサービスから各集約の更新処理を呼び出す
- 理由
ただし、上記ルールは原則であって、無理に守る必要はない。プロジェクトの状況に応じてやれる範囲でやれば良い。
- 例外パターン
- UIの利便性を優先
- 画面操作上、複数の集約をまとめて(同期的に)作成するシナリオのケース
- 技術的な仕組みの不足
- 結果整合性を実現するアーキテクチャが存在しない(イベントメッセージ基盤)
- グローバルトランザクションの強制
- 2フェーズコミットなどのグローバルトランザクションがルール上/業務上必須なケース
- クエリパフォーマンス改善
- 1SQLで複数の集約(エンティティ)の情報をまとめて取ってきた方が性能は良い
- UIの利便性を優先
コーディングに役立つ法則
デメテルの法則(最小知識の法則)
- 理由
- 呼出先の呼出先まで知ってる前提だと、密結合になってしまうから
- 直接的に触れるオブジェクト上のプロパティ(メソッドや変数)までしか参照しちゃダメ
- 直接触れるオブジェクトとは
- 自分自身 / インスタンス変数 / メソッドの引数 / メソッド内でインスタンス化
public class MyClass {
private Piyo piyo;
public void myMethod(Hoge hoge) {
hoge.xxx; // OK(引数のプロパティ)
hoge.getXxx(); // OK(引数のプロパティ)
hoge.fuga.yyy; // NG(引数のプロパティのプロパティ)
hoge.fuga.getYyy(); // NG(引数のプロパティのプロパティ)
this.piyo.zzz; // OK(インスタンス変数のプロパティ)
this.piyo.fuga.yyy; // NG(インスタンス変数のプロパティのプロパティ)
Fuga fuga = new Fuga();
fuga.yyy; // OK(インスタンス生成したオブジェクトのプロパティ)
fuga.piyo.zzz; // NG(インスタンス生成したオブジェクトのプロパティのプロパティ)
}
}命じろ、尋ねるな(Tell-Don’t-Ask)の法則
- 理由
- 呼び出し先のオブジェクトの状態を尋ねるということは、呼び出し元が呼び出し先の内部の情報を必要以上を知ることになる=密結合
- オブジェクト内部の状態により処理を切り分けたりするのは、各オブジェクトの責務
悪い例
// 悪い例
public class Hoge {
public string fuga;
public void doSomething() {
// do something
};
}
Hoge hoge = new Hoge();
if (hoge.fuga.equals("piyo")) {
hoge.doSomething();
}良い例
// 良い例
public class Hoge {
private string fuga;
public void doSomething() {
if (!this.fuga.equals("piyo")) {
return;
}
// do something
}
}
Hoge hoge = new Hoge();
hoge.doSomething();集約での(リポジトリの)依存性の注入を避ける
- 前提
- どうやら依存先の集約の情報を取得するという文脈で述べてあるっぽい
- 理由(たぶん)
- 関心事を分離することでシンプルに
- ドメインは参照や永続化は気にせず、加工・計算などに集中する
- 集約でDBにアクセスしだすと、ここが性能面のボトルネックになる
- 関心事を分離することでシンプルに
- 対応方式
- 依存先の集約の情報を事前に取得して、メインの集約のメソッド引数で渡す
- 疑問点
- 事前に依存先の情報を取得してる時点で、呼び出し元のサービスはこの集約の依存先の情報を把握している必要があり密結合に感じる
- メインの集約のデータ取得、DB反映はどこでやるのだろう?
- アプリケーションサービスでデータ取得=>集約で計算=>アプリケーションサービスでDB登録の流れ?
- これも密結合に感じるし、実装次第で「計算したけどDB反映してない」が起こる
11. 「ファクトリ」〜複雑な生成をユビキタス言語でシンプルに〜
ファクトリ
- DDDにおけるファクトリとは
- 特定の集約で、別の集約(オブジェクト)を組み立てる
- サービスで、別の境界づけられたコンテキストのオブジェクトを、ローカルの境界づけられたコンテキストの型のオブジェクトに変換して生成
- ファクトリを使う理由(Evans氏)
- 複雑なオブジェクトや集約のインスタンス生成の責務を他のオブジェクトに移すこと
ファクトリの設計
- コンストラクタ
- 生成範囲がそのオブジェクトに閉じる場合
- 集約配下のオブジェクトを生成したり、別の集約を生成したりと言うのはコンストラクタの責務ではない
- 集約ルート上のファクトリメソッド
- コンストラクタの責務を超えるような複雑な生成処理が必要な場合に導入する
- 多態性(ポリモーフィズム)を用いて実クラス決定
- クライアントが具象クラスを意識させたくない
- 集約配下の複数オブジェクトの生成
- 集約配下の各オブジェクトのコンストラクタを呼び出す(可視性はprotected)
- 各オブジェクトへの参照を持つ集約ルートオブジェクトを組み立て、返却する
- 他の集約オブジェクトの組み立て
- (たぶん)他の集約自身が集約のファクトリ or コンストラクタは提供する
- 他の集約の中身を知っていて、それを組み立てるのは密結合すぎておかしいため
- その上で、ユビキタス言語において土台となる集約が、他の集約のファクトリメソッドを呼び出すイメージ
- 例えば「チャンネルにスレッドを立てる」のであれば、チャンネル集約ルートにて、スレッド集約の生成を行う
- スレッド生成時にチャンネルIDを渡すことで、スレッドが生成元のチャンネルに間違いなく所属することが担保できる
- (たぶん)他の集約自身が集約のファクトリ or コンストラクタは提供する
- 多態性(ポリモーフィズム)を用いて実クラス決定
- ファクトリの中で不変条件のアサートも行う
- コンストラクタの責務を超えるような複雑な生成処理が必要な場合に導入する
- ドメインサービスに実装するファクトリ
- 別の境界づけられたコンテキストの集約オブジェクトを取得する際に利用する
- その際、ローカルの境界づけられたコンテキストの型に変換する処理も行う
- 疑問点
- 別の境界づけられたコンテキストのオブジェクトはリポジトリが提供しても良さそうなので、ちょっと悩ましい
デザインパターン
ファクトリを実装するにあたって参考になるデザインパターンをEvans氏が紹介している
12. 「リポジトリ」〜集約の永続化を担当〜
リポジトリ
- リポジトリとは
- 一般にはデータの格納庫を抽象化したもの
- DDDでは集約の格納の取得を担当する
- オブジェクトが(DBなどの実体を意識せず)メモリ上にあると錯覚させる(Evans氏)
- 配置
- ドメイン層にインターフェースを、インフラストラクチャ層に具象クラスを配置
- リポジトリの実装変更がドメイン層に影響しない
- ドメイン層にインターフェースを、インフラストラクチャ層に具象クラスを配置
- トランザクション管理
- リポジトリを呼び出す、アプリケーションサービス側で行う
リポジトリでの集約(データ)の取得および格納
-
集約取得の流れ
- アプリケーションサービスはリポジトリ経由で集約を取得する
- リポジトリはDBから取得したデータを元に、ファクトリで集約を取得する

-
集約格納の流れ
- アプリケーションサービスはファクトリで集約を取得する
- リポジトリは受け取った集約をDBに格納する
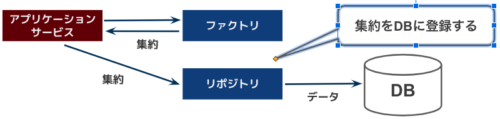
-
[疑問点] 複数エンティティから構成される集約をDBデータを元に生成するファクトリメソッド引数の型はどうすべき?
- リポジトリは複数テーブルからデータを取得し、集約ルートに定義されたファクトリメソッドを呼び出す
- ファクトリメソッドの引数の型の候補
- 各テーブルの項目を引数として渡す?
- 項目が多いと冗長。1対多の項目を指定するのも難しい
- 専用のDTOに格納して渡す?
- 無駄な詰め替えが必ず発生することになってしまう
- 各ドメインエンティティのコンストラクタでインスタンスを生成して引数として渡す?
- 集約内部に外側からアクセスすることになってしまう
- リポジトリがほとんどファクトリの役割を持ってしまっているのではないか
- 各テーブルの項目を引数として渡す?
- 正直、どれも今ひとつ
- ファクトリメソッドの引数の型の候補
- 案1) リポジトリが集約のファクトリメソッドを持つのはどうだろうか?
- 上記の3.を選択するぐらいなら、リポジトリが集約のファクトリメソッドを提供する方がシンプルではないか
- リポジトリが集約のファクトリクラスであると考えれば違和感は少ない
- 案2) ファクトリ内でリポジトリを呼び出す
- リポジトリはDBからデータを取得してドメインエンティティに変換する責務だけを持たせる。集約は気にしない
- 集約ルートが持つファクトリメソッド内で、リポジトリを使って複数テーブルからドメインエンティティの形でデータを取得してきて、集約を構成して返却する
- 「集約内でリポジトリをDIするな」という話が以前あったのでそこが微妙か
- 書籍記載の形式よりも 案1、案2の方が良さそうに思える。個人的には集約を完全なロジッククラスにしたほうがテストとかも書きやすいので、案1を推したい
- リポジトリは複数テーブルからデータを取得し、集約ルートに定義されたファクトリメソッドを呼び出す
コレクション指向と永続指向
- コレクション指向
- RDBにデータを格納する
- O/Rマッパーで集約オブジェクトとテーブルレコードをマッピングして格納する
- × 複数のテーブルから集約を構成する必要があるし、追加/更新が大変
- ○ 部分更新が可能
- ○ RDBとしての機能を使える(ASID特性、正規化、joinできる)
- 永続指向
- NoSQLデータベースにデータを格納する
- 集約全体を一つのドキュメントとして格納する
- シリアライズ、デシリアライズが必要
- ○ 集約全体をシンプルに取得できるし、シンプルに更新できる(追加と更新の区別も不要)
- × 常に全体更新
- × RDBとしての機能が使えない(ASID特性、正規化、joinできる)。代わりにCAP特性
- ○ 分散処理に向いてる
13. 「境界づけられたコンテキストの統合」〜分散システム設計〜
統合と分散システム
- 統合
- 複数の「境界づけられたコンテキスト」間で情報を連携することを統合と呼ぶ
- 分散システム
- 作業のコンピュータをネットワークで接続して作業を分担しながら稼働しているシステム
- 8つの原則
- ネットワークは信頼できない
- ある程度の遅延が常に発生する
- 帯域幅には限りがある
- ネットワークはセキュアではない
- ネットワーク構成は変換する
- 管理者は複数である
- 転送コストはゼロではない
- ネットワークは一様では無い
- コンテキスト間のデータ交換フォーマット
- 共有カーネル
- プログラミング言語のシリアライズ機能
- 中間フォーマット(XML、JSONなど)
- 同時に定義したMIMEタイプ
イベントの通知
- 8章で紹介されているドメインイベントを利用する
- 通知方法
- MQなどのメッセージング基盤を利用する
- REST APIを利用する
- 必要なクラス
- イベントを格納するNotificationクラス
- イベントを読み出すNotificationReaderクラス
RESTサービスを使った統合アーキテクチャ
- リアルタイム連携
- ローカル側が、必要な時にリアルタイムでリモート側のAPIを呼び出して情報を取得する
- メリット/デメリット
- ○ リアルタイムの最新のデータを取得できる
- ○ 構成がシンプルで設計しやすい
- × リモート側の状態(ダウン、遅延)の影響を直接受ける
- バッチ/タイマー連携
- 定期的にリモート側のAPIを呼び出してローカル側に情報を取り込む
- メリット/デメリット
- ○ リモート側の状態の影響を受けにくい
- ○ 構成がシンプルで設計しやすい
- × まとめて公開するための専用のAPIが必要
- × pull型なのでリアルタイム連携ではない
メッセージングを使った統合アーキテクチャ
- シンプル版
- リモート側でpublishされたイベントを、ローカル側のイベントリスナーが受け取り、処理を行う
- メリット/デメリット
- ○ REST APIが不要
- ○ RabbitMQなどのミドルウェア側で可用性や性能を個別に考えられる
- × メッセージの前後関係が逆転する可能性がある
- × メッセージが二回送られる可能性がある
- × イベントを発生させた側は、受信側の処理が行われたかを検知できない
- 追跡トラッカー導入版
- 追跡トラッカーとは集約に対して1対1で存在する値オブジェクト
- 集約のプロパティ(変数やメソッド)単位に最終イベント日時を管理しておく
- イベントを受け取ったら、追跡トラッカーが保持している関連する最終イベント日時を元に本当に更新して良いかどうかを判断する
- メリット/デメリット(シンプル版に比べて)
- ○ メッセージの逆転や二回送信の問題を解決できる
- × プロパティの数だけ追跡トラッカー実装が必要になる
- 追跡トラッカーとは集約に対して1対1で存在する値オブジェクト
- 長期プロセス導入版
- 送信側(ローカル側)が受信側(リモート側)の処理完了を検知したい場合に導入する
- 長期プロセス、サーガ、プロセスマネージャとも言われる
- シンプルには、受信側(リモート側)で処理完了時にイベントを発行して、送信側(ローカル側)が受け取って終了処理を行うっぽい
- 専用のライブラリを導入する方法もありそうな感じ
14. 「アプリケーション」〜ドメインモデルを利用するクライアント〜
UI層とアプリケーション層
- UI層(ユーザーインターフェース、プレゼンテーション)
- サーバーサイドでレンダリングするWebシステム
- フロントエンドでレンダリングするWebシステム(ReactやVueなどのフレームワークを利用)
- スマホアプリ
- アプリケーション層
- 責務は、利用用途(ユースケース)に応じて調整を行うこと
- ユースケース毎にメソッドを提供する
ドメイン層とUI層間のデータの受け渡し
- 複数の集約情報をDTO(Data Transfer Object)に詰め替えて渡す
- DTOに値を詰め替えるDTOアセンブラが必要
- 集約の内部情報の公開が必要になるのが欠点?
- 集約側にアセンブラを準備する?というのは悪手だと思う。ドメイン層が外側の事情を知る事になる
- クリーンアーキテクチャ的には外側が内側に依存しても問題ない気がする
- 複数の集約への参照を保持するDPO(Data Payload Object)を渡す
- 詰め替えが不要
- ドメインモデルをUI層に公開するメリット/デメリット
- ○ 性能はよい(詰め替え処理、メモリ使用およびGC)
- △ 結合度は高くなる(UIがドメインに強く依存する)
- ○ 型による妥当性チェックができる
- ○ コード量(詰め替えが無いので少ない)
- △ 複数クライアントの考慮が難しい?(それぞれDPOを作ればいいのでは?という気はする)
- △ 情報漏洩リスク(書いてないけど、公開すべきでない情報が間違って漏れてしまうリスクがある)
- 個人的にはこれが一番気になっている
- ユースケースに最適化したクエリにより取得する
- リポジトリでユースケースに最適化したクエリを作り、複数集約を(DTOではなく)値オブジェクトに格納して返却する
複数のドメイン(境界づけられたコンテキスト)間での集約の統合
- アプリケーション層で、各ドメインにアクセスして情報を収集する
- 新しいドメイン(境界づけられたコンテキスト)を作って、そこから複数のドメインにアクセスする
- ドメインモデル貧血症になるけど割り切る
- (書いてないけど)UI層から複数のドメインにアクセスするのが一般的な気がする
ビューとプレゼンテーションモデル
- ビュー
- UIの描画を行う
- プレゼンテーションモデル
- UIの内容を抽象化し、UI固有の状態やUI固有のロジックを持つ
- UI固有の状態はここのみに定義し、ドメインモデル側には定義しない
- DTOやDPOを通じて渡ってきた情報を、プレゼンテーションモデルにマッピングする処理が必要
さいごに
この本自体は考えるきっかけとしてはすごくよかったですが「Why so?」を書いてないケースが多くて、そこは別書籍やWebサイトで補足する必要があります。
その上でも納得できない部分もそれなりにあるのでそのまま鵜呑みにせず、プロジェクトでどこまで導入するか取捨選択しながら、納得できる範囲で導入するのが良さそうだ、と思いました。