Docker Desktop for Mac でWordPressを動かしているのですが、ある日データベース(mysql)が壊れてWordPressを起動するとlog sequence number is in the futureエラーが発生するようになってしまいました。
またいつか発生しそうな予感がするので、対応方法をメモしておきます。
エラー詳細
WordPressの画面にアクセスしようとすると、mysqlのDockerコンテナが再起動してしまいます。画面上は以下のように表示されます。
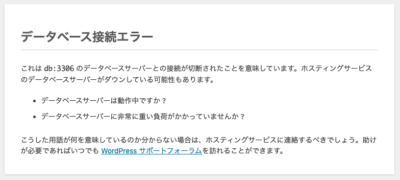
Dockerコンテナのログを確認したところ、以下のエラーが出力されていました。
[ERROR] InnoDB: Page [page id: space=63, page number=406] log sequence number 289034868 is in the future! Current system log sequence number 276954729.
[ERROR] InnoDB: Your database may be corrupt or you may have copied the InnoDB tablespace but not the InnoDB log files. Please refer to http://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html for information about forcing recovery.該当PageのLSN(log sequence number)が、システムログの値より未来の値になっているよ。DBが壊れたか、InnoDBのテーブルスペースはコピーしたけどInnoDBのログファイルをコピーし忘れた可能性があるよ。
というようなことが書いてあります。
よく知らない単語が二つあったので調べました。
- InnoDB
- MySQLのテーブルのデータを格納するための、ストレージエンジン。v5.5以降はデフォルト
- ACID特性とトランザクションを完全サポートしている
- 他にMyISAM、MERGE、MEMORY、ARCHIVE、CSV、FEDERATEDなどがある
- 詳細はこちら
- LSN(log sequence number)
- ログシーケンス番号で、 Redoログのある時点に対応する値。
- クラッシュリカバリに利用される
- 詳細はこちら
どうやら、テーブルスペースの対象Pageに記録されているLSNと、Redoログに記録されているLSNを、データも含めて同期させられれば良さそうな気配です。
障害のトリガー
今回、Docker Desktopのメモリの設定を変更するために再起動したのですが、その際にmysqlのコンテナを起動したままにしてました。
それ以降、エラーが発生するので、おそらくこれがトリガーになったようです。
RedoログのLSNを確認する
以下のコマンドで確認できます。
mysql -u root -p
mysql>show engine innodb status;
(抜粋)
---
LOG
---
Log sequence number 276954738
Log flushed up to 276954738
Pages flushed up to 276954738
Last checkpoint at 276954729LSNのLast checkpointの値(276954729)が、エラーログのCurrent system log sequence numberと一致していますね。
テーブルスペース側はデータ格納されたPageそれぞれにLSNの値が格納されているようで、リカバリ実行には「ページのLSN > RedoログのLSNの場合はリカバリ不要」みたいな考え方でリカバリするみたいです。
対応
ログに出ているURLを確認
エラーログに以下のように出力されているので、このURLをまずは確認してみます。
Please refer to http://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html for information about forcing recovery.
読んでみると、デフォルトのinnodb_force_recovery = 0だと強制リカバリなしだけど、この値を大きくしていくにつれて、強制リカバリせずにエラーを無視してくれるようになるようです。ただし、これは強制リカバリ動作なくデータをダンプしたりすることが目的で、この設定をしただけで何かが解決する訳ではありませんでした。
変更方法は、DockerコンテナにAttach Shellして、例えば以下のように/etc/mysql/my.cnfを直接書き換えるだけです。
[mysqld]
innodb_force_recovery = 61〜6まで設定して動作確認してみたのですが、1〜5までは同じエラーが出て強制再起動がかかったのですが、6に設定したところ何エラーも発生せずブログの画面も表示されました。このことから、データは特に壊れておらず、Redoログ上のLSNの値を大きくしてあげれば良さそうと判断しました。
ちなみに、6を設定した状態でログインなどDBを更新する処理を行おうとすると以下のようなエラーが出て、テーブルがread onlyになっていることがわかります。
Can't lock file (errno: 165 - Table is read only) for query UPDATE `wp_usermeta` SET xxxxxx;RedoログのLSNの値を大きくする
断念した方法
まずは、 https://yakst.com/ja/posts/53 を参考にLSNを直接変更する方法を試してみました。
gdbとpgrepをインストールします。
apt update
apt install -y gdb
gdb --version
> GNU gdb (Debian 8.2.1-2+b3) 8.2.1
apt install -y procps
pgrep --version
> pgrep from procps-ng 3.3.15次に、以下のように実行してみたのですが、以下のようにうまく行きません。
gdb --pid `pgrep -x mysqld`
(gdb) print log_sys->lsn
No symbol table is loaded. Use the "file" command.
(gdb) set log_sys->lsn = 300000000
No symbol table is loaded. Use the "file" command.
(gdb) continue
> The program is not being run.調べたところ、ビルドしたバイナリにデバッグシンボルがないためらしいです。
おそらく、このへんでブレークポイントをはって、そこで上記を実行すれば良さそうなのですが、log_sys->lsnが存在する行にブレークポイントを貼る方法がわかりませんでした。
既存で起動しているmysqldプロセスにアタッチする方法ではなく、gdbの中でmysqldを起動する方法も試してみましたが、目的の関数で止めるところまでできましたが、カレントコンテキストの変数にアクセスする部分がどうしてもうまく行かず諦めました。
gdb mysqld
(gdb) br recv_recovery_from_checkpoint_start
(gdb) run
Thread 1 "mysqld" hit Breakpoint 1, 0x000056323cb36844 in recv_recovery_from_checkpoint_start(unsigned long) ()
(gdb) print log_sys->lsn
'log_sys' has unknown type; cast it to its declared typeというわけで、この方法は断念しました。。
うまく行った方法
こちらを参考にさせていただきました。
https://qiita.com/tigersun2000/items/8f8eca92e70bcc26a882
新しいテーブルを作って、データをインサートしまくってLSNの値を進める方法です。
記載されているSQLをほぼそのまま参考にさせていただいて実行しました。
mysql -u root -p -D wordpress
mysql> create table hoge (fuga text);
mysql> insert into hoge values (REPEAT('xxxxxxxxxx' , 1000));
mysql> insert into hoge select * from hoge; # これをなんども実行
mysql> drop table hoge;
mysql> show engine innodb status;
---
LOG
---
Log sequence number 395436272
Log flushed up to 395436272
Pages flushed up to 383113673
Last checkpoint at 381358664これで、LSNの値を大幅に進めることができましたね。
実際に、ブログの画面を開いたり、ログインして投稿を記載してみましたが、特に問題なく動くようになりました。
さいごに
結構対応には時間がかかってしまいました。
エンジニア以外の人がこれに遭遇したらほぼ詰みじゃないか、と思います。まあそんなに発生しないのだとは思いますが。
改めてバックアップの大切さを感じますね。
なお、今回の対処は相当危ういとは思いますので、参考にする場合は自己責任でお願いします。