業務で Elasticsearch を触ることになったので、多少今更感ありますが、環境構築・データ登録・マッピング定義・検索など、一通りのユースケースを試してみようと思います。
Elasticsearch version: 7.11
環境構築
以下のドキュメントを元に、Dockerを使ってElasticsearchをインストールしようと思います。
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/docker.html
docker-compose.ymlを作成
まずは、docker-compose.ymlを作成します。
とりあえずはドキュメントの内容をそのままコピーでOKだと思います。
version: '2.2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.11.0
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.11.0
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.11.0
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge実行と確認
以下のコマンドで実行します。
docker-compose upDockerエンジンのメモリ割り当てが足りないとExit 137エラーが発生すると思います。
4GB程度は割り当てると問題ないようです。(自分は5GB割り当ててます)
確認したところ問題なく動いているようです。
curl -X GET "localhost:9200/_cat/nodes?v=true&pretty"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.18.0.4 43 93 7 0.28 0.62 0.43 cdhilmrstw - es03
172.18.0.3 45 93 7 0.28 0.62 0.43 cdhilmrstw - es01
172.18.0.2 58 93 7 0.28 0.62 0.43 cdhilmrstw * es02Cerebro(管理ツール)の導入
管理ツールとしてCelebroを導入しようと思います。
docker-compose.ymlに追記
servicesにcerebroの定義を追加します。
ポイントは、9000番ポートを露出するところぐらいです。
services:
# ===== ここから =====
cerebro:
image: lmenezes/cerebro:0.9.3
ports:
- 9000:9000
# ===== ここまで =====
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.11.0実行と確認
以下のコマンドで実行します。
docker-compose upブラウザで、 http://localhost:9000 にアクセスして、Node Address に http://host.docker.internal:9200 を指定します。
ちなみに、host.docker.internalはDockerコンテナ内からホストOSのホスト名を指します。
Connectをクリックすると、Cerebroの管理画面が立ち上がります。
ここでは、REST APIの実行やINDEX定義の確認などをやっていくことになると思います。
データ(document)登録
Cerebroのrest画面からAPIを実行して、データを登録しました。(本記事ではcurl形式で記載します)
戦国武将3人(織田信長・徳川家康・武田信玄)のデータを登録してみました。
curl -H 'Content-type: application/json' -XPUT 'http://localhost:9200/warloads/_doc/1' -d '{
"name": "織田 信長",
"countries": ["尾張", "美濃", "伊勢", "摂津", "河内", "大和"],
"introduction": "織田 信長(おだ のぶなが、天文3年5月12日〈1534年6月23日〉 - 天正10年6月2日〈1582年6月21日〉)は、日本の戦国時代から安土桃山時代にかけての武将、戦国大名。三英傑の一人。",
"birthday": "1534-06-23",
"age": 49
}'
curl -H 'Content-type: application/json' -XPUT 'http://localhost:9200/warloads/_doc/2' -d '{
"name": "徳川 家康",
"countries": ["三河"],
"introduction": "徳川 家康(とくがわ いえやす、旧字体:德川 家康)は、戦国時代から江戸時代初期にかけての武将・戦国大名[1]・天下人。安祥松平家9代当主で徳川家や徳川将軍家、御三家の始祖。旧称は松平 元康(まつだいら もとやす)。戦国時代に終止符を打ち、朝廷より征夷大将軍に任せられ、1603年、260年間続く江戸幕府を開いた[1]。三英傑のひとりである。",
"birthday": "1543-01-31",
"age": 75
}'
curl -H 'Content-type: application/json' -XPUT 'http://localhost:9200/warloads/_doc/3' -d '{
"name": "武田 信玄",
"countries": ["甲斐", "信濃", "駿河", "飛騨"],
"introduction": "武田 信玄(たけだ しんげん) / 武田 晴信(たけだ はるのぶ)は、戦国時代の武将、甲斐の守護大名・戦国大名。甲斐源氏の嫡流にあたる甲斐武田家第19代当主。諱は晴信、通称は太郎(たろう)。姓名は源晴信 「信玄」とは(出家後の)法名で、正式には徳栄軒信玄。1915年(大正4年)11月10日に従三位を贈られる",
"birthday": "1523-11-03",
"age": 53
}'特に事前準備は必要なく、document(データ)を投入すると、自動的にindex(RDBにおけるテーブルに相当)とマッピング定義(documentおよびfieldがどう保存され、どうインデックスされるか)が作成されます。
今回、自動で作成されたマッピング定義は以下の通りです。
{
"warloads": {
"mappings": {
"properties": {
"age": {
"type": "long"
},
"birthday": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"countries": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"introduction": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}自動で作成されたマッピング定義は残念ながら期待通りではありませんでした。
| プロパティ | 期待する型 | 実際の型 |
|---|---|---|
| age | long | long |
| birthday | date | textとkeywordのmulti-field |
| countries | keyword(配列) | text(配列)とkeyword(配列)のmulti-field |
| introduction | text | textとkeywordのmulti-field |
| name | keyword | textとkeywordのmulti-field |
次は、このマッピング定義を期待する型に変更していこうと思います。
データタイプ
各プロパティ(フィールド)に使えるデータタイプはこちらです。
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/mapping-types.html
色々あるのですが、今回使うやつだけ一旦紹介しておきます。
- 数値型
-
long・integer・short・byte・unsigned_longなどの整数を扱う型、double・float・half_float・scaled_floatなどの小数を扱う型がある
-
-
date型- 年月日時分秒ミリ秒まで格納できる
- ナノ秒まで格納したい場合は、
date_nanosを用いる
-
keyword型- 文字列をトークナイズ(単語分割)せずにそのまま格納する
- ソートや集計に利用される。トークナイズされないので、完全一値検索しかできない。
- 部分一致や全文検索のようなことをやりたい場合は、
textを用いる
-
text型- 文字列をアナライズ(文字変換、トークナイズ、トークン変換)してから、格納する
- 転置インデックス(各トークンがどのdocで出現するか)が記録されている
-
match_phrasequeryで、全文検索ができる - 基本的には集計には利用できないが、
fielddata: trueを指定すれば集計できる - その場合、トークン単位で集計される
- メモリに乗っかるので、JVMのヒープサイズは要注意
- array型
- 明示的なarray型は存在しない
- 複数データ(配列データ)を登録しようとすると、勝手にarrayとして登録される
明示的マッピング指定
明示的なマッピング指定のドキュメントはこちらです。
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/explicit-mapping.html
Except for supported mapping parameters, you can’t change the mapping or field type of an existing field. Changing an existing field could invalidate data that’s already indexed.
If you need to change the mapping of a field in a data stream’s backing indices, see Change mappings and settings for a data stream.
If you need to change the mapping of a field in other indices, create a new index with the correct mapping and reindex your data into that index.
とあるので、v7.9で導入されたdata streamsを使ってる場合はマッピングを変更できるみたいですが、それ以外のケースは既存のマッピング定義を変更することはできないみたいです。
そのため、マッピング定義を変更したい場合は、新しくindexを作って既存indexから新規indexにデータをreindexするような手順になりますが、今回は一旦indexを削除して作り直してから、改めてデータを投入しようと思います。
まず、既存のindexを削除しました。Cerebro上で対象インデックスを右クリックで削除できます。
次に、期待する型で明示的にマッピングを指定したインデックスを作成します。
curl -H 'Content-type: application/json' -XPUT 'http://localhost:9200/warloads' -d '{
"mappings": {
"properties": {
"age": {
"type": "long"
},
"birthday": {
"type": "date",
"format": "yyyy-MM-dd"
},
"country": {
"type": "keyword",
"ignore_above": 256
},
"introduction": {
"type": "text"
},
"name": {
"type": "keyword",
"ignore_above": 256
}
}
}
}'Cerebro上でマッピング定義を確認すると以下のように、期待通りの内容になっていました。
{
"warloads": {
"mappings": {
"properties": {
"age": {
"type": "long"
},
"birthday": {
"type": "date",
"format": "yyyy-MM-dd"
},
"countries": {
"type": "keyword",
"ignore_above": 256
},
"introduction": {
"type": "text"
},
"name": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}最後に、(既述の方法で)データを追加したしたところ、新しいマッピング定義で無事データが登録されていました。
query
queryの種類もたくさんあるので、詳しくは以下のドキュメントを見てもらうのがいいとも思います。
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/query-dsl.html
ここでは、使う頻度が高そうなものを紹介しておきます。
match_all(全件検索)
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/query-dsl-match-all-query.html
一番シンプルなqueryです。全件ヒットします。
curl -H 'Content-type: application/json' -XPOST 'http://localhost:9200/warloads/_search' -d '{
"query": {
"match_all": {}
}
}'
# GETリクエストだと、全件検索になる
curl -H 'Content-type: application/json' -XGET 'http://localhost:9200/warloads/_search'検索結果は以下のようになります。
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "warloads",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"name": "織田 信長",
"countries": [
"尾張",
"美濃",
"伊勢",
"摂津",
"河内",
"大和"
],
"introduction": "織田 信長(おだ のぶなが、天文3年5月12日〈1534年6月23日〉 - 天正10年6月2日〈1582年6月21日〉)は、日本の戦国時代から安土桃山時代にかけての武将、戦国大名。三英傑の一人。",
"birthday": "1534-06-23",
"age": 49
}
},
// 以下省略
]
}
}初めて検索結果が出てきたので、各項目の意味を説明します。
-
took: 検索にかかった実行時間(ミリ秒) -
time_out: 検索がタイムアウトしたかどうか -
_shards: 検索されたシャードの数。シャードとはIndex内のドキュメントを複数ノードで分散管理するための論理的な入れ物 -
hits: 検索結果-
total.value: ヒットしたドキュメントの数 -
hits: 検索結果のデータ(この件数はリクエスト時に、"site": 30のように指定できる)-
_id: ドキュメントのID。ドキュメント詳細をGet APIで取得する際にこのIDを指定する -
_score: 関連性スコア。このスコアの値が大きい順に表示される
-
-
match
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/query-dsl-match-query.html
指定されたテキスト、数値、日付、ブール値に(完全)一致するドキュメントを返却します。
例えば、「long型のageが49」で検索するクエリは以下の通りです。結果織田信長1件がヒットします。
curl -H 'Content-type: application/json' -XPOST 'http://localhost:9200/warloads/_search' -d '{
"query": {
"match": {
"age": "49"
}
}
}'数値や日付、ブール値はそのままなのでわかりやすいと思いますが、テキストに関しては分かりにくいので詳しく解説します。
そもそもテキストには keyword型 と text型 の大きく二つの型があります。
- keyword は、トークナイズ(単語分割)されず、基本的にはテキストがそのまま登録される
- 例)
織田 信長=>織田 信長全体で1つとして管理される
- 例)
- text は、トークナイズされるので、トークンに分けて管理されます
- 例)
織田 信長=>織・田・信・長の4つのトークンに分けられて管理される- kuromojiなどの日本語専用のアナライザーを入れるともっといい感じに分割されるが、デフォルトのStandard Analyzerだと日本語は文字単位分割されるw
- 例)
keyword型へのmatchクエリ
まずは keyword型 に対して、matchクエリをかけてみます。
「keyword型のnameが織田 信長」で検索するクエリは以下の通りです。これは1件ヒットします。
curl -H 'Content-type: application/json' -XPOST 'http://localhost:9200/warloads/_search' -d '{
"query": {
"match": {
"name": "織田 信長"
}
}
}'次に、クエリを"query": "織田と書き換えると、1件もヒットしません。
これは、端的には"織田 信長" ≠ "織田"だからです。keyword型の場合は、クエリと完全一致するものがヒットします。
text型へのmatchクエリ
text型の場合は、Elasticsearchにデータを投入する際に、アナライザーによってトークンに分割してデータが登録されています。
今回だとindtoductionというフィールドには、「その他Tipsのanalysis」に書いてある方法で確認すると、織田信長・武田信玄・徳川家康の紹介文は、以下のようにトークンに分割されて登録されているはずです。
# 織田信長
織, 田, 信, 長, お, だ, の, ぶ, な, が, 天, 文, 3, 年, 5, 月, 12, 日, 1534, 年, 6, 月, 23, 日, 天, 正, 10, 年, 6, 月, 2, 日, 1582, 年, 6, 月, 21, 日, は, 日, 本, の, 戦, 国, 時, 代, か, ら, 安, 土, 桃, 山, 時, 代, に, か, け, て, の, 武, 将, 戦, 国, 大, 名, 三, 英, 傑, の, 一, 人
# 武田信玄
武, 田, 信, 玄, た, け, だ, し, ん, げ, ん, 武, 田, 晴, 信, た, け, だ, は, る, の, ぶ, は, 戦, 国, 時, 代, の, 武, 将, 甲, 斐, の, 守, 護, 大, 名, 戦, 国, 大, 名, 甲, 斐, 源, 氏, の, 嫡, 流, に, あ, た, る, 甲, 斐, 武, 田, 家, 第, 19, 代, 当, 主, 諱, は, 晴, 信, 通, 称, は, 太, 郎, た, ろ, う, 姓, 名, は, 源, 晴, 信, 信, 玄, と, は, 出, 家, 後, の, 法, 名, で, 正, 式, に, は, 徳, 栄, 軒, 信, 玄, 1915, 年, 大, 正, 4, 年, 11, 月, 10, 日, に, 従, 三, 位, を, 贈, ら, れ, る
# 徳川家康
徳, 川, 家, 康, と, く, が, わ, い, え, や, す, 旧, 字, 体, 德, 川, 家, 康, は, 戦, 国, 時, 代, か, ら, 江, 戸, 時, 代, 初, 期, に, か, け, て, の, 武, 将, 戦, 国, 大, 名, 1, 天, 下, 人, 安, 祥, 松, 平, 家, 9, 代, 当, 主, で, 徳, 川, 家, や, 徳, 川, 将, 軍, 家, 御, 三, 家, の, 始, 祖, 旧, 称, は, 松, 平, 元, 康, ま, つ, だ, い, ら, も, と, や, す, 戦, 国, 時, 代, に, 終, 止, 符, を, 打, ち, 朝, 廷, よ, り, 征, 夷, 大, 将, 軍, に, 任, せ, ら, れ, 1603, 年, 260, 年, 間, 続, く, 江, 戸, 幕, 府, を, 開, い, た, 1, 三, 英, 傑, の, ひ, と, り, で, あ, るこのデータに対して、「text型のintroductionが織田 信長」というクエリで検索をかけてみました。
{
"query": {
"match": {
"introduction": "織田 信長"
}
}
}結果、織田信長と武田信玄の2つのドキュメントがヒットします。
武田信玄の紹介文には織田信長は出てこないのに、武田信玄がヒットするのは違和感があります。
これは、検索クエリの方もアナライザーによってトークナイズされるためです。
織田 信長は、デフォルトのStandard Analyzerによって織・田・信・長の4つのトークンに分割され、かつ、デフォルトだとOR条件なので、これらに一つでもマッチするトークンがあるドキュメントがヒットします。
武田信玄の紹介文には田と信の二つのトークンが含まれているのでヒットし、徳川家康の紹介文には一つも含まれないのでヒットしません。
織田信長だけをヒットさせるためには、以下のようにオペレータをandに変えてあげればOKです。
織田信長1件だけがヒットします。
{
"query": {
"match": {
"introduction": {
"query": "織田 信長",
"operator": "and"
}
}
}
}これで完璧なようにも見えるのですが、実はまだ微妙です。
例えば、以下のようにクエリを織長田 信に変えても、ヒットしてしまいます(涙)
{
"query": {
"match": {
"introduction": {
"query": "織長田 信",
"operator": "and"
}
}
}
}Elasticsearchの導入目的として全文検索をやりたいというケースが多いと思いますが、全文検索するのであれば、通常文字順も考慮したいのではないでしょうか。
この文字順まで考慮して検索するのが、次に紹介するmatch_phraseクエリになります。
match_phrase
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/query-dsl-match-query-phrase.html
match_phrase クエリでは、トークンを跨いだフレーズを元に検索することができます。
以下のように、織田 信長というフレーズで紹介文を検索すると期待通り織田信長1件だけがヒットします。
{
"query": {
"match_phrase": {
"introduction": "織田 信長"
}
}
}一方で、織長田 信で検索した場合は、期待通り1件もヒットしません。
Boolean query
検索する場合、AND条件・OR条件・NOT条件を組み合わせて検索したくなると思います。
これを実現するのが、以下のクエリです。
| クエリ | 説明 |
|---|---|
| must | AND条件。スコアに影響する |
| filter | AND条件。スコアに影響しない |
| should | OR条件 |
| must_not | NOT条件 |
「紹介文に戦国大名が含まれる」 and 「生年月日が1930-01-01以降」という条件で検索してみます。
結果織田信長と徳川家康の2件がヒットしました。
{
"query": {
"bool": {
"must": [
{ "match_phrase": { "introduction": "戦国大名" } },
{ "range": { "birthday": { "gte": "1530-01-01" } } }
]
}
}
}上記のクエリのmustをfilterに変更しても、検索結果は変わりません。ただし、関連性スコアが上記の例だと0になります。
上記のクエリのmustをshouldに変更すると、武田信玄も含めて3件ヒットします。
最後に、must・should・must_notの3つを組み合わせた検索条件を試してみて終わりにします。
「名前が織田 信長or徳川 家康or武田 信玄」 and 「年齢が50以上」 and 「生年月日が1530-01-01以前」という条件で検索しています。結果徳川家康1件だけヒットします。
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{ "match": { "name": "織田 信長" } },
{ "match": { "name": "徳川 家康" } },
{ "match": { "name": "武田 信玄" } }
]
}
},
{
"range": { "age": { "gte": 50 } }
},
{
"bool": {
"must_not": {
"range": { "birthday": { "lte": "1530-01-01" } }
}
}
}
]
}
}
}その他Tips
analysis
text型のフィールドにデータを登録した際にアナライズされるかを確認することがでできます。
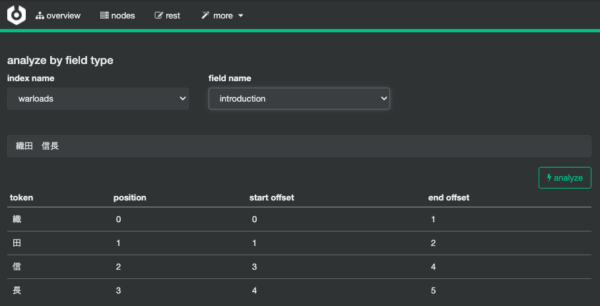
Celebro > more > analysis で開いた画面で、実行できます。
以下の例は、warloadsインデックスのintroductionというフィールドに織田 信長というデータを追加した時のアナライズ結果です。このフィールドのアナライザーはデフォルト設定(Standard Anaylzer)なので日本語は一文字ずつトークナイズされて、全角スペースはトークンフィルターで除外されているのだと分かります。
さいごに
Elasticsearchを真面目に触ったのは初めてでしたが、ある程度付き合い方がわかってきた気がしました。
今回は書かなかったのですが、highlightやaggregate、についてもある程度は試してみたので、気が向いたいたら別記事で書いてみようと思います。
=> (追記)書きました。
https://rinoguchi.net/2021/03/elasticsearch-part2.html
今回のコードは一応以下で公開してます(docker-compose.ymlだけですが)。
https://github.com/rinoguchi/elasticsearch_sample